RAC interview questions and answers:
Is rcp and/or rsh required for normal Oracle RAC operation ?
rcp"" and ""rsh"" are not required for normal Oracle RAC operation. However in older versions ""rsh"" and ""rcp"" should to be enabled for Oracle RAC and patchset installation. In later releases, ssh is used for these operations.
Note Oracle Enterprise Manager uses rsh.
What is Cache Fusion and how does this affect applications?
Cache Fusion is a new parallel database architecture for exploiting clustered computers to achieve scalability of all types of applications. Cache Fusion is a shared cache architecture that uses high speed low latency interconnects available today on clustered systems to maintain database cache coherency. Database blocks are shipped across the interconnect to the node where access to the data is needed. This is accomplished transparently to the application and users of the system. As Cache Fusion uses at most a 3 point protocol, this means that it easily scales to clusters with a large numbers of nodes. For more information about cache fusion see the following links:
Additional Information can be found at:
Note: 139436.1 Understanding 9i Real Application Clusters Cache Fusion
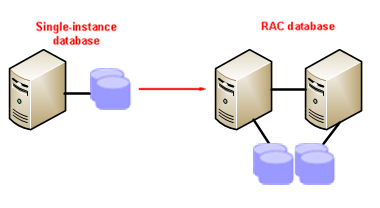
Is it difficult to transition (migrate) from Single Instance to Oracle RAC?
If the cluster and the cluster software are not present, these components must be installed and configured. The Oracle RAC option must be added using the Oracle Universal Installer, which necessitates the existing DB instance must be shut down. There are no changes necessary on the user data within the database. However, a shortage of freelists and freelist groups can causecontention with header blocks of tables and indexes as multiple instances vie for the same block. This may cause a performance problem and require data partitioning. However, the need for these changes should be rare.
Recommendation: apply automatic space segment management to perform these changes automatically. The free space management will replace the freelists and freelist groups and is better. The database requires one Redo thread and one Undo tablespace for each instance, which are easily added with SQL commands or with Enterprise Manager tools.
NOTE: With ORacle RAC 11g Release 2, you do not neet to pre-create redo threads or undo tablespaces if you are using Oracle Managed Files (EG ASM).
Datafiles will need to be moved to either a clustered file system (CFS) so that all nodes can access them. Oracle recommends the use of Automatic Storage Management (ASM) Also, the MAXINSTANCES parameter in the control file must be greater than or equal to number of instances you will start in the cluster.
For more detailed information, please see Migrating from single-instance to RAC in the Oracle Documentation.
With Oracle Database 10g Release 2, $ORACLE_HOME/bin/rconfig tool can be used to convert Single instance database to RAC. This tool takes in a xml input file and convert the Single Instance database whose information is provided in the xml. You can run this tool in "verify only" mode prior to performing actual conversion. This is documented in the Oracle RAC Admin book and a sample xml can be found $ORACLE_HOME/assistants/rconfig/sampleXMLs/ConvertToRAC.xml. This tool only supports databases using a clustered file system or ASM. You cannot use it with raw devices. Grid Control 10g Release 2 provides a easy to use wizard to perform this function.
4456047>> (shutdown immediate hangs) as you convert
is release noted as well.
Oracle Enterprise Manager includes workflows to assiste with migrations. (I.E. Migrating to ASM, Creating Standby, Converting Standby to RAC etc) The migration is automated in Enterprise Manager Grid Control 10.2.0.5.
What are the dependencies between OCFS and ASM in Oracle Database 10g ?
In an Oracle RAC 10g environment, there is no dependency between Automatic Storage Management (ASM) and Oracle Cluster File System (OCFS).
OCFS is not required if you are using Automatic Storage Management (ASM) for database files. You can use OCFS on Windows( Version 2 on Linux ) for files that ASM does not handle - binaries (shared oracle home), trace files, etc. Alternatively, you could place these files on local file systems even though it's not as convenient given the multiple locations.
If you do not want to use ASM for your database files, you can still use OCFS for database files in Oracle Database 10g.
href="http://asm.us.oracle.com/pdf/ASM%20and%20OCFS%20Positioning.pdf">ASM and OCFS Positioning
Do we have to have Oracle Database on all nodes?
Each node of a cluster that is being used for a clustered database will typically have the database and Oracle RAC software loaded on it, but not actual datafiles (these need to be available via shared disk). For example, if you wish to run Oracle RAC on 2 nodes of a 4-node cluster, you would need to install the clusterware on all nodes, Oracle RAC on 2 nodes and it would only need to be licensed on the two nodes running the Oracle RAC database. Note that using a clustered file system, or NAS storage can provide a configuration that does not necessarily require the Oracle binaries to be installed on all nodes.
With Oracle RAC 11g Release 2, if you are using policy managed databases, then you should have the Oracle RAC binaries accessible on all nodes in the cluster.
What software is necessary for Oracle RAC? Does it have a separate installation CD to order?
Oracle Real Application Clusters is an option of Oracle Database and therefore part of the Oracle Database CD. With Oracle 9i, Oracle 9i RAC is part of Oracle9i Enterprise Edition. If you install 9i EE onto a cluster, and the Oracle Universal Installer (OUI) recognizes the cluster, you will be provided the option of installing RAC. Most UNIX platforms require an OSD installation for the necessary clusterware. For Intel platforms (Linux and Windows), Oracle provides the OSD software within the Oracle9i Enterprise Edition release.
With Oracle Database 10g, Oracle RAC is an option of EE and available as part of SE. Oracle provides Oracle Clusterware on its own CD included in the database CD pack.
Please check the certification matrix (Note 184875.1) or with the appropriate platform vendor for more information.
With Oracle Database 11g Release 2, Oracle Clusterware and Automatic Storage Management are installed as a single set of binaries called the grid infrastructure. The media for the grid infrastructure is on a separate CD or under the grid directory. For standalone servers, Automatic Storage Management and Oracle Restart are installed as the grid infrastructure for a standalone server which is installed from the same media.
What Application Design considerations should I be aware of when moving to Oracle RAC?
The general principals are that fundamentally no different design and coding practices are required for RAC however application flaws in execution or design have a higher impact in RAC. The performance and scalability in RAC will be more sensitive to bad plans or bad schema design. Serializing contention makes applications less scalable. If your customer uses standard SQL and schema tuning, it solves > 80% of performance problems
Some of the scaleability pitfalls they should look for are:
* Serializing contention on a small set of data/index blocks
--> monotonically increasing key
--> frequent updates of small cached tables
--> segment without automatic segment space management (ASSM) or Free List Group (FLG)
* Full table scans
--> Optimization for full scans in 11g can save CPU and latency
* Frequent invalidation and parsing of cursors
--> Requires data dictionary lookups and synchronizations
* Concurrent DDL ( e.g. truncate/drop )
Look for:
* Indexes with right-growing characteristics
--> Use reverse key indexes
--> Eliminate indexes which are not needed
* Frequent updated and reads of “small” tables
--> “small”=fits into a single buffer cache
--> Use Sparse blocks ( PCTFREE 99 ) to reduce serialization
* SQL which scans large amount of data
--> Perhaps more efficient when parallelized
--> Direct reads do not need to be globally synchronized ( hence less CPU for global cache )
What kind of HW components do you recommend for the interconnect?
The general recommendation for the interconnect is to provide the highest bandwith interconnect, together with the lowest latency protocol that is available for a given platform. In practice, Gigabit Ethernet with UDP has proven sufficient in every case it has been implemented, and tends to be the lowest common denominator across platforms.
Is it a good idea to add anti-virus software to my RAC cluster?
For customers who choose to run anti-virus (AV) software on their database servers, they should be aware that the nature of AV software is that disk IO bandwidth is reduced slightly as most AV software checks disk writes/reads. Also, as the AV software runs, it will use CPU cycles that would normally be consumed by other server processes (e.g your database instance). As such, databases will have faster performance when not using AV software. As some AV software is known to lock the files whilst it scans then it is a good idea to exclude the Oracle Datafiles/controlfiles/logfiles from a regular AV scan
Is a relink required for the clusterware home after an OS upgrade?
In 10g and 11.1, Oracle Clusterware binaries cannot be relinked. However, the client shared libraries on that home can be relinked, in most cases there should not be a need to relink them. See Note:743649.1 on how to do that.
In 11.2, there are some executables in the Grid home that can and should be re-linked after an OS upgrade. The procedure to do this is:
As root:
# cd Grid_home/crs/install
# perl rootcrs.pl -unlock
As the grid infrastructure for a cluster owner:
$ export ORACLE_HOME=Grid_home
$ Grid_home/bin/relink
As root again:
# cd Grid_home/crs/install
# perl rootcrs.pl -patch
Is there a need to renice LMS processes in Oracle RAC 10g Release 2?
LMS processes should be running in RT by default since 10.2, so there's NO need to renice them, or otherwise mess with them.
Check with ps -efl:
0 S oracle 31191 1 0 75 0 - 270857 - 10:01 ? 00:00:00 ora_lmon_appsu01
0 S oracle 31193 1 5 75 0 - 271403 - 10:01 ? 00:00:07 ora_lmd0_appsu01
0 S oracle 31195 1 0 58 - - 271396 - 10:01 ? 00:00:00 ora_lms0_appsu01
0 S oracle 31199 1 0 58 - - 271396 - 10:01 ? 00:00:00 ora_lms1_appsu01
7th column, if it is 75 or 76 then this is Time Share, 58 is Real Time.
You can also use chrt to check:
LMS (Real Time):
$ chrt -p 31199
pid 31199's current scheduling policy: SCHED_RR
pid 31199's current scheduling priority: 1
LMD (Time Share)
$ chrt -p 31193
pid 31193's current scheduling policy: SCHED_OTHER
pid 31193's current scheduling priority: 0
How can a NAS storage vendor certify their storage solution for Oracle RAC ?
As of January 2007 the OSCP has been discontinued!!
Please refer to this link on OTN for details on Oracle RAC Technologies Matrix (storage being part of it).
Old Answer text:
They should obtain an OCE test kit and complete the required Oracle RAC tests. They can submit the request for an OCE kit to ocesup_ie@oracle.com.
My customer has an XA Application with a Oracle RAC Database, can I do Load Balancing across the Oracle RAC instances?
No, not in the traditional Oracle Net Services Load Balancing. We have written a document that explains the ** best practices for 9i, 10g Release 1 and 10g Release 2** . With the Oracle Database 10g Services, life gets easier. To understand services, read the Oracle RAC Admin and Deployment Guide for 10g Release 2 Chapter 6.
With Oracle RAC 11g, Oracle provides transparent support for XA global transactions in an Oracle RAC environment which supports load balancing with Oracle Net Services across Oracle RAC instances.
Should the SCSI-3 reservation bit be set for our Oracle Clusterware only installation?
If you are using only Oracle Clusterware(no Veritas CM), then you don't need to have SCSI-3 PGR enabled, since Oracle Clusterware does not require it for IO fencing. If the reservation is set, then you'll get the inconsistent results. So ask your storage vendor to disable the reservation.
Veritas RAC requires that the storage array support SCSI-3 PGR, since this is how Veritas handles IO fencing. This SCSI-3 PGR is set at the array level; for example EMC hypervolume level.
Additional info:
1) If the SCSI-3 PGR bit is set on a storage array (or an a LUN, this does not matter in this case), it only enables SCSI3 PGR capabilities. If set, a cluster or application using this piece of storage may make use of SCSI3 PGR. Oracle Solaris Cluster and Veritas Cluster may use SCSI3 PGR under certain circumstances, Oracle Clusterware does not (as far as I can tell). So, whether the bit is set or not, as long as no component on the host makes use of it, nothing will change.
2) Oracle Clusterware as well as ASM do not make use of or leverage SCSI3 PGR. Only 3rd party clustering stack components will use it; eg, VCS, SFRAC, HACMP, and cluster volume managers. If you don't ever plan on installing or are using 3rd party cluster stack components, then SCSI3 PGR LUNs should be transparent to you. However, I would question why the storage team would even setup LUNs w/ PR arbitrarily. This just adds another management step and it could be confusing from storage management perspective.
How do I determine which node in the cluster is the "Master" node?
For the cluster synchronization service (CSS), the master can be found by searching ORACLE_HOME/log/nodename/cssd/ocssd.log where it is either the Oracle HOME for the Oracle Clusterware (this is the Grid Infrastructure home in Oracle Database 11g Release 2).
For master of a enqueue resource with Oracle RAC, you can select from v$ges_resource. There should be a master_node column.
Is Infiniband supported for the Oracle RAC interconnect?
IP over IB is supported. RDS on Linux is supported with 10.2.0.3 forward. Qlogic (formerly SilverStorm) is the supported RDS vendor.
Watch certify for updates. As other platforms adopt RDS, we will expand support. Latest update: RDSv1 is supported on Solaris with 10.2.0.4.
There are no plans to support uDAPL or ITAPI protocols.
See Note: 751343.1 for more details.
Where can I find a list of supported solutions to ensure NIC availability / redundancy (for the interconnect) per platform?
IBM AIX - available solutions:
Etherchannel (OS based)
HACMP based network failover solution
More information: Note: 296856.1
HP HP/UX - available solutions:
APA - Auto Port Aggregation (OS based)
MC/Serviceguard based network failover solution
Combination of both solutions
More information: Note: 296874.1 and Auto Port Aggregation (APA) Support Guide
Sun Solaris - available solutions:
Sun Trunking (OS based)
Sun IPMP (OS based)
Sun Cluster based network failover solution (clprivnet)
More information for Oracle RAC 10g and Oracle RAC 11g Release 1:
My Oracle Support Note: 283107.1 - Configure IPMP for the Oracle VIP and IPMP introduction
My Oracle Support Note: 368464.1 - How to Setup IPMP as Cluster Interconnect
More information for Oracle RAC 11g Release 2:
My Oracle Support Note: 1069584.1 - Solaris IPMP and Trunking for the cluster interconnect in Oracle Grid Infrastructure
href="http://database.us.oracle.com/pls/htmldb/f?p=301:75:::::P75_ID:12630">In Solaris 10, do we need Sun Clusterware to provide redundancy for the interconnect and multiple switches?
Linux - available solutions:
Bonding
More information: Note: 298891.1
href="http://database.us.oracle.com/pls/htmldb/f?p=301:75:::::P75_ID:6680">How do I use multiple network interfaces to provide High Availability and/or Load Balancing for my interconnect with Oracle Clusterware?
Windows - available solutions:
Teaming
On Windows teaming solutions to ensure NIC availability are usually part of the network card driver.
Thus, they depend on the network card used. Please, contact the respective hardware vendor for more information.
OS independent solution:
Redundant Interconnect Usage enables load-balancing and high availability across multiple (up to four) private networks (also known as interconnects).
Oracle RAC 11g Release 2, Patch Set One (11.2.0.2) enables Redundant Interconnect Usage as a feature for all platforms, except Windows.
On systems that use Solaris Cluster, Redundant Interconnect Usage will use clprivnet.
Does Oracle support Oracle RAC in Solaris containers (a.k.a. Solaris Zones)?
YES for Oracle RAC 10g Rel. 2 onwards. While Global containers have been supported for a while, Oracle added support for local containers recently after the local containers were extended to allow direct hardware modification.
Lifting this restriction allow Oracle Clusterware to operate on hardware resources such as the network for the Oracle VIP directly, enabling Oracle RAC to run in local containers.
More information about Solaris container support can be found in Oracle Certify.
How to use VLANs in Oracle RAC?
It is Oracle's standing recommendation to separate the various types of communication in an Oracle RAC cluster as much as possible. This general recommendation is the basis for the following separation of communication:
Each node in an Oracle RAC cluster must have at least one public network.
Each node in an Oracle RAC cluster must have at least one private network, also referred to as "interconnect".
Each node in an Oracle RAC cluster must have at least an additional network interface, if the shared storage is accessed using a network based connection.
In addition Oracle RAC and Oracle Clusterware deployment best practices recommend that the interconnect be deployed on a stand-alone, physically seperate, dedicated switch, since it represents the easiest to configure and most secure as well as stable configuration. Many customers, however, have consolidated or prefer to consolidate these stand-alone switches into larger managed switches.
Depending on the level of consolidation that is performed on the switch level, the switch thereby may become a single point of failure. Hardware redundancy within an enterprise switch may mitigate some of the risks, but there are limitations as far as maintenance operations are concerned. Mainaining switch redundancy is therefore highly recommended. Another consequence of this consolidation is a merging of IP networks on a single shared switch, segmented by VLANs in various levels, which include, but are not limited to:
Sharing the same switch (and network channel) for private and public communication
Sharing the same switch (and network channel) for the private communication of more than one cluster.
Sharing the same switch (and network channel) for private communication and shared storage access.
While an increasingly powerful network infrastructure makes it more and more interesting for customers to consolidate network communication on fewer physical networks, it needs to be remembered that the latency and bandwidth requirements as well as availability requirements of the Oracle RAC / Oracle Clusterware interconnect IP network are more in-line with high performance computing. In a more abstract way, one should not look at the interconnect as a network, but rather as a backplane to connect the memory of the cluster nodes.
While observing the bandwidth requirements, Oracle generally recommends maintaining a 1:1 relation when VLANs are used in any possible way and if the usage of VLANs cannot be avoided. In this context, it needs to be noted that bandwidth and latency are not the only concerns. Security, ease of management, and unintended but possible side-effects of using a shared resource such as multicast flooding or spanning tree re-convergence also need to be considered. In detail:
Sharing the same switch (and network channel) for private and public communication
and deploying the interconnect on a VLAN in this environment, there should be a 1:1 mapping of the VLAN to a non-routable subnet and the VLAN should not span multiple VLANs (tagged) or multiple switches.
Sharing the same switch (and network channel) for the private communication of more than one cluster,
one VLAN per cluster is recommended for the purpose of a "cleaner" management and security (see above).
Further consolidation, such as using only one VLAN for all clusters, is supported, but not recommended.
It is supported to use the same, consolidated network infrastructure (within the same security domain) for various clusters without the use of VLANs, while separated channels are recommended.
Sharing the same switch (and network channel) for private communication and shared storage access
is supported, if the underlying network infrastructure recognizes and prioritizes network based communication to the storage.
What is SCAN?
Single Client Access Name (SCAN) is a single name that allows client connections to connect to any database in an Oracle cluster independently of which node in the cluster the database (or service) is currently running. The SCAN should be used in all client connection strings and does not change when you add/remove nodes from the cluster. SCAN allows clients to use EZConnect or the this JDBC URL.
sqlplus system/manager@ sales1-scan:1521/oltp
jdbc:oracle:thin:@sales1-scan:1521/oltp
The SCAN is defined as a single name resolving to 3 IP addresses in either the cluster's GNS or your corporate DNS.
** Click here for more details on SCAN.
Are there any issues for the interconnect when sharing the same switch as the public network by using VLAN to separate the network?
Oracle RAC and Oracle Clusterware deployment best practices recommend that the interconnect be deployed on a stand-alone, physically seperate, dedicated switch.
Many customers, however, have consolidated these stand-alone switches into larger managed switches. A consequence of this consolidation is a merging of IP networks on a single shared switch, segmented by VLANs. There are caveats associated with such deployments.
The Oracle RAC cache fusion protocol exercises the IP network more rigorously than non-RAC Oracle databases. The latency and bandwidth requirements as well as availability requirements of the Oracle RAC / Oracle Clusterware interconnect IP network are more in-line with high performance computing.
Deploying the Oracle RAC / Oracle Clusterware interconnect on a shared switch, segmented by a VLAN may expose the interconnect links to congestion and instability in the larger IP network topology.
If deploying the interconnect on a VLAN, there should be a 1:1 mapping of the VLAN to a non-routable subnet and the VLAN should not span multiple VLANs (tagged) or multiple switches.
Deployment concerns in this environment include Spanning Tree loops when the larger IP network topology changes, Assymetric routing that may cause packet flooding, and lack of fine grained monitoring of the VLAN/port.
I get the following error starting my Oracle RAC database, what do I do?
WARNING: No cluster interconnect has been specified.
This simply means that you neither have a cluster_interconnects parameter set for the database, nor was there any cluster interconnect specification found in the OCR, so that the private interconnect is picked at random by the database, and hence the warning.
You can either set the cluster_interconnects parameter in the initialization file (spfile / pfile) of the datbase to specify a private interconnect IP, OR you can use "oifcfg setif" (type "oifcfg" for help) to classify a certain network for as the cluster interconnect network.
$ oifcfg getif
eth0 138.2.236.0 global public
eth2 138.2.238.0 global cluster_interconnect
Note that oifcfg enables you to specify "local" as well as "global" settings. With Oracle Clusterware 10g Rel. 1 and Rel. 2 as well as Oracle Clusterware 11g Rel. 1, it is, however, only supported to use global settings. If the hardware (network interface) meant to be used for the interconnect is not the same on all nodes in the cluster, the configuration needs to be changed on the hardware / OS level accordingly.
Are block devices supported for OCR, Voting Disks, and ASM devices?
Block Devices are only supported on Linux. On other Unix platforms, the directio symantics are not applicable (or rather not implemented) for block devices.
Note: The support for raw/block devices is scheduled for Oracle Database 12g. The Oracle Database 10g OUI does not support block devices however Oracle Clusterware and ASM do.
With Oracle RAC 11g Release 2, the Oracle Universal Installer and the Configuration Assistants do not support raw or block devices anymore. The Command Line Interfaces still support raw/block devices and hence the Oracle Clusterware files can be moved after the initial installation.
If my OCR and Voting Disks are in ASM, can I shutdown the ASM instance?
No. You will have to stop the Oracle Clusterware stack on the node on which you need to stop the Oracle ASM instance. Either use "crsctl stop cluster -nnode_name" or "crsctl stop crs" for this purpose.
I have changed my spfile with alter system set parameter_name =.... scope=spfile. The spfile is on ASM storage and the database will not start.
How to recover:
In $ORACLE_HOME/dbs
. oraenv
sqlplus "/ as sysdba"
startup nomount
create pfile='recoversp' from spfile
/
shutdown immediate
quit
Now edit the newly created pfile to change the parameter to something sensible.
Then:
sqlplus "/ as sysdba"
startup pfile='recoversp' (or whatever you called it in step one).
create spfile='+DATA/GASM/spfileGASM.ora' from pfile='recoversp'
/
N.B.The name of the spfile is in your original init(instance_name).ora so adjust to suit
shutdown immediate
startup
quit
What combinations of Oracle Clusterware, Oracle RAC and ASM versions can I use?
See Note:337737.1 for a detailed support matrix. Basically the Clusterware version must be at least the highest release of ASM or Oracle RAC. ASM must be at least 10.1.0.3 to work with 10.2 database.
Note: With Oracle Database 11g Release 2, You must upgrade Oracle Clusterware and ASM to 11g Release 2 at the same time.
I had a 3 node Oracle RAC. One of the nodes had to be completely rebuilt as a result of a problem. As there are no backups, What is the proper procedure to remove the 3rd node from the cluster so it can be added back in?
Follow the documentation for removing a node but you can skip all the steps in the node-removal doc that need to be run on the node being removed, like steps 4, 6 and 7 (See Chapter 10 of Oracle RAC Admin and Deployment Guide). Make sure that you remove any database instances that were configured on the failed node with srvctl, and listener resources also, otherwise rootdeltenode.sh will have trouble removing the nodeapps.
Just running rootdeletenode.sh isn't really enough, because you need to update the installer inventory as well, otherwise you won't be able to add back the node using addNode.sh. And if you don't remove the instances and listeners you'll also have problems adding the node and instance back again.
bug: 5929611 filed) for a remove node is Note: 269320.1
Does Weblogic (WLS) support Services, FAN/FCF, and the Load Balancing Advisory (LBA) with Oracle RAC?
Currently the integration is incomplete however it is being actively worked upon.
the following:
href="http://fmwdocs.us.oracle.com/doclibs/fmw/E10285_01/web.1111/e13737/oracle_rac.htm#i1084474">Using WebLogic Server with Oracle RAC chapter in the Oracle® Fusion
href="http://fmwdocs.us.oracle.com/doclibs/fmw/E10285_01/web.1111/e13737/oracle_rac.htm#i1084474">Middleware Configuring and Managing JDBC for Oracle WebLogic Server book
The recommendation from Oracle Fusion Middleware is to use WLS Multi pools with Oracle RAC.
Are jumbo frames supported for the RAC interconnect?
Yes. For details see Note:341788.1 Cluster Interconnect and Jumbo Frames
Are Sun Logical Domains (ldoms) supported with RAC?
Sun Logical Domains (ldoms) are supported with Oracle Database (both single instance and RAC). Check certify for the latest information.
What is Standard Edition Oracle RAC?
As of Oracle Database 10g, a customer who has purchased Standard Edition is allowed to use the Oracle RAC option within the limitations of Standard Edition(SE). For licensing restrictions you should read the Oracle Database License Doc. At a high level this means that you can have a max of 4 sockets in the cluster, you must use ASM for all database files. As of Oracle Database 11g Release 2, ASM includes ACFS (a cluster file system). ASM Cluster File System (ACFS) or a local OS file system must be used to store all non-database files including Oracle Home, Application and system files, and User files
NOTE: 3rd party clusterware and clustered file systems(other than ASM) are not supported. This includes OCFS and OCFS2.
Here is the text from the appropriate footnote in the Price List (as of Jan2010, please check price list for any changes):
Oracle Database Standard Edition can only be licensed on servers that have a maximum capacity of 4 sockets. If licensing by Named User Plus, the minimum is 5 Named User Plus licenses. Oracle Database Standard Edition, when used with Oracle Real Application Clusters, may only be licensed on a single cluster of servers supporting up to a total maximum capacity of 4 sockets.
NOTE: This means that the server capacity must meet the restriction even if the sockets are empty, since they count towards capacity.
Where do I find Oracle Clusterware binaries and ASM binaries with Oracle Database 11g Release 2?
With Oracle Database 11g Release 2, the binaries for Oracle Clusterware and Automatic Storage Management (ASM) are distributed in a single set of binaries called the grid infrastructure. To install the grid infrastructure, go to the grid directory on your 11g Release 2 media and run the Oracle Universal Installer). Choose the Grid Infrastructure for a Cluster. If you are install ASM for a single instance of Oracle Database on a Standalone Server, choose the Grid Infrastructure for a Standalone Server. This installation includes Oracle Restart.
I have the 11.2 Grid Infrastructure installed and now I want to install an earlier version of Oracle Database (11.1 or 10.2), is this supported ?
Yes however you need to "pin" the nodes in the cluster before trying to create a database using an earlier version of Oracle Database (IE not 11.2). The command to pin a node is crsctl pin css -n nodename. You should also apply the patch for Bug 8288940 to make DBCA work in an 11.2 cluster.
I get an error with DBCA from 10.2 or 11.1 after I have installed the 11.2 Grid Infrastructure?
You will need to apply the patch for Bug 8288940 to your database home in order for it to recognize ASM running from the new grid infrastructure home. Also make sure you have "pinned" the nodes.
crsctl pin css -n nodename
Can I use iSCSI storage with my Oracle RAC cluster?
For iSCSI, Oracle has made the statement that, as a block protocol, this technology does not require validation for single instance database. There are many early adopter customers of iSCSI running Oracle9i and Oracle Database 10g. As for Oracle RAC, Oracle has chosen to validate the iSCSI technology (not each vendor's targets) for the 10g platforms - this has been completed for Linux and Windows. For Windows we have tested up to 4 nodes - Any Windows iSCSI products that are supported by the host and storage device are supported by Oracle. We don't support NAS devices for Windows, however some NAS devices (eg NetApp) can also present themselves as iSCSI devices. If this is the case then a customer can use this iSCSI device with Windows as long as the iSCSI device vendor supports Windows as an initiator OS. No vendor-specific information will be posted on Certify.
What would you recommend to customer, Oracle Clusterware or Vendor Clusterware (I.E. HP Service Guard, HACMP, Sun Cluster, Veritas etc.) with Oracle Real Application Clusters?
You will be installing and using Oracle Clusterware whether or not you use the Vendor Clusterware. Oracle Clusterware provides a complete clustering solution and is required for Oracle RAC or Automatic Storage Management (including ACFS).
Vendor clusterware is only required with Oracle 9i RAC. Check the certification matrix in MyOracleSupport for details of certified vendor clusterware.
When configuring the NIC cards and switch for a GigE Interconnect should it be set to FULL or Half duplex in Oracle RAC?
You must use Full Duplex for all network communication. Half Duplex means you can only either send OR receive at a time.
Can I use Oracle RAC in a distributed transaction processing environment?
YES. Best practices is to have all tightly coupled branches of a distributed transaction running on an Oracle RAC database must run on the same instance. Between transactions and between services, transactions can be load balanced across all of the database instances.
Prior to Oracle RAC 11g, you must use services to manage DTP environments. By defining the DTP property of a service, the service is guaranteed to run on one instance at a time in an Oracle RAC database. All global distributed transactions performed through the DTP service are ensured to have their tightly-coupled branches running on a single Oracle RAC instance.
Oracle RAC 11g provides transparent support for XA global transactions in an Oracle RAC environment and you do not need to use DTP services.
Can I run Oracle 9i RAC and Oracle RAC 10g in the same cluster?
YES. However Oracle Clusterware (CRS) will not support a Oracle 9i RAC database so you will have to leave the current configuration in place. You can install Oracle Clusterware and Oracle RAC 10g into the same cluster. On Windows and Linux, you must run the 9i Cluster Manager for the 9i Database and the Oracle Clusterware for the 10g Database. When you install Oracle Clusterware, your 9i srvconfig file will be converted to the OCR. Both Oracle 9i RAC and Oracle RAC 10g will use the OCR. Do not restart the 9i gsd after you have installed Oracle Clusterware. With Oracle Clusterware 11g Release 2, the GSD resource will be disabled by default. You only need to enable this resource if you are running Oracle 9i RAC in the clsuter.
Remember to check certify for details of what vendor clusterware can be run with Oracle Clusterware.
For example on Solaris, your Oracle 9i RAC will be using Sun Cluster. You can install Oracle Clusterware and Oracle RAC 10g in the same cluster that is running Sun Cluster and Oracle 9i RAC.
What storage is supported with Standard Edition Oracle RAC?
As per the licensing documentation, you must use ASM for all database files with SE Oracle RAC. There is no support for CFS or NFS.
From Oracle Database 10g Release 2 Licensing Doc:
Oracle Standard Edition and Oracle Real Application Clusters (RAC) When used with Oracle Real Application Clusters in a clustered server environment, Oracle Database Standard Edition requires the use of Oracle Clusterware. Third-party clusterware management solutions are not supported. In addition, Automatic Storage Management (ASM) must be used to manage all database-related files, including datafiles, online logs, archive logs, control file, spfiles, and the flash recovery area. Third-party volume managers and file systems are not supported for this purpose.
What are the restrictions on the SID with an Oracle RAC database? Is it limited to 5 characters?
The SID prefix in 10g Release 1 and prior versions was restricted to five characters by install/config tools so that an ORACLE_SID of upto max of 5+3=8 characters can be supported in an Oracle RAC environment. The SID prefix is relaxed up to 8 characters in 10g Release 2, see bug4024251 for more information.
With Oracle RAC 11g Release 2, SIDs in Oracle RAC with Policy Managed database are dynamically allocated by the system when the instance starts. This supports a dynamic grid infrastructure which allows the instance to start on any server in the cluster.
Does Oracle Clusterware or Oracle Real Application Clusters support heterogeneous platforms?
Oracle Clusterware and Oracle Real Application Clusters do not support heterogeneous platforms in the same cluster. Enterprise Manager Grid Control supports heterogeneous platforms. We do support machines of different speeds and size in the same cluster. All nodes must run the same operating system (I.E. they must be binary compatible). In an active data-sharing environment, like Oracle RAC, we do not support machines having different chip architectures.
I want to use rconfig to convert a single instance to Oracle RAC but I am using raw devices in Oracle RAC. Does rconfig support RAW ?
No. rconfig supports ASM and shared file system only.
How many NICs do I need to implement Oracle RAC?
At minimum you need 2: external (public), interconnect (private). When storage for Oracle RAC is provided by Ethernet based networks (e.g. NAS/nfs or iSCSI), you will need a third interface for I/O so a minimum of 3. Anything else will cause performance and stability problems under load. From an HA perspective, you want these to be redundant, thus needing a total of 6.
Can we designate the place of archive logs on both ASM disk and regular file system, when we use SE RAC?
Yes, - customers may want to create a standby database for their SE RAC database so placing the archive logs additionally outside ASM is OK.
Can my customer use Veritas Agents to manage their Oracle RAC database on Unix with SFRAC installed?
For details on the support of SFRAC and Veritas Agents with RAC 10g, please see Note 397460.1 Oracle's Policy for Supporting Oracle RAC 10g (applies to Oracle RAC 11g too) with Symantec SFRAC on Unix and Note 332257.1 Using Oracle Clusterware with Vendor Clusterware FAQ
Can I run more than one clustered database on a single Oracle RAC cluster?
You can run multiple databases in a Oracle RAC cluster, either one instance per node (w/ different databases having different subsets of nodes in a cluster), or multiple instances per node (all databases running across all nodes) or some combination in between. Running multiple instances per node does cause memory and resource fragmentation, but this is no different from running multiple instances on a single node in a single instance environment which is quite common. It does provide the flexibility of being able to share CPU on the node, but the Oracle Resource Manager will not currently limit resources between multiple instances on one node. You will need to use an OS level resource manager to do this.
Can I run Oracle RAC 10g with Oracle RAC 11g?
Yes. The Oracle Clusterware should always run at the highest level. With Oracle Clusterware 11g, you can run both Oracle RAC 10g and Oracle RAC 11g databases. If you are using ASM for storage, you can use either Oracle Database 10g ASM or Oracle Database 11g ASM however to get the 11g features, you must be running Oracle Database 11g ASM. It is recommended to use Oracle Database 11g ASM.
Note: When you upgrade to 11g Release 2, you must upgrade both Oracle Clusterware and Automatic Storage Management to 11g Release 2. This will support Oracle Database 10g and Oracle Database 11g (both RAC and single instance).
Yes, you can run Oracle 9i RAC in the cluster as well. 9i RAC requires the clusterware that is certified with Oracle 9i RAC to be running in addition to Oracle Clusterware 11g.
Can I have multiple public networks accessing my Oracle RAC?
Yes, you can have multiple networks however with Oracle RAC 10g and Oracle RAC 11g, the cluster can only manage a single public network with a VIP and the database can only load balance across a single network. FAN will only work on the public network with the Oracle VIPs.
Oracle RAC 11g Release 2 supports multiple public networks. You must set the new init.ora parameter LISTENER_NETWORKS so users are load balanced across their network. Services are tied to networks so users connecting with network 1 will use a different service than network 2. Each network will have its own VIP.
I could not get the user equivalence check to work on my Solaris 10 server when trying to install 10.2.0.1 Oracle Clusterware. The install ran fine without issue. << Message: Result: User equivalence check failed for user "oracle". >>
Cluvfy and the OUI tries to find SSH on Solaris at /usr/local/bin. Workaround is to create a softlink from /usr/bin/ssh to /usr/local/bin.
Note: User equivalence is required for installations (IE using OUI) and patching. DBCA, NETCA, and DBControl also require user equivalence.
Is it supported to install Oracle Clusterware and Oracle RAC as different users?
Yes, Oracle Clusterware and Oracle RAC can be installed as different users. The Oracle Clusterware user and the Oracle RAC user must both have OINSTALL as their primary group. Every Database home can have a different OSDBA group with a different username.
Why does the NOAC attribute need to be set on NFS mounted RAC Binaries?
The noac attribute is required because the installer determines sharedness by creating a file and checking for that file’s existance on remote node. If the noac attribute is not enabled then this test will incorrectly fail. This will confuse installer and opatch. Some other minor issues issues with spfile in the default $ORACLE_HOME/dbs will definitely be affected.
We are using Transparent Data Encryption (TDE).
We create a wallet on node 1 and copy to nodes 2 & 3. Open the wallet and we are able to select encrypted data on all three nodes.
Now, we want to REKEY the MASTER KEY. What do we have to do?
After a re-key on node one, 'alter system set wallet close' on all other nodes, copy the wallet with the new master key to all other nodes, 'alter system set wallet open identified by "password"; on all other nodes to load the (obfuscated) master key into node's SGA.
How do I check for network problems on my interconect?
1. Confirm that full duplex is set correctly for all interconnect links on all interfaces on both ends. Do not rely on auto negotiation.
2. ifconfig -a will give you an indication of collisions/errors/overuns and dropped packets
3. netstat -s will give you a listing of receive packet discards, fragmentation and reassembly errors for IP and UDP.
4. Set the udp buffers correctly
5. Check your cabling
Note: If you are seeing issues with RAC, RAC uses UDP as the protocol. Oracle Clusterware uses TCP/IP.
The Veritas installation document on page 219 asks for setting LD_LIBRARY_PATH_64. Should I remove this?
Yes You do not need to set LD_LIBRARY_PATH for Oracle.
Why does netca always creates the listener which listens to public ip and not VIP only?
This is for backward compatibility with existing clients: consider pre-10g to 10g server upgrade. If we made upgraded listener to only listen on VIP, then clients that didn't upgrade will not be able to reach this listener anymore.
Does changing uid or gid of the Oracle User affect Oracle Clusterware?
There are a lot of files in the Oracle Clusterware home and outside of the Oracle Clusterware home that are chgrp'ed to the appropriate groups for security and appropriate access. The filesystem records the uid (not the username), and so if you exchange the names, now the files are owned by the wrong group.
Can we output the backupset onto regular file system directly (not onto flash recovery area) using RMAN command, when we use SE RAC?
Yes, - customers might want to backup their database to offline storage so this is also supported.
How do I use DBCA in silent mode to set up RAC and ASM?
If you already have an ASM instance/diskgroup then the following creates a RAC database on that diskgroup (run as the Oracle user):
$ORACLE_HOME/bin/dbca -silent -createDatabase -templateName General_Purpose.dbc -gdbName $SID -sid $SID -sysPassword $PASSWORD -systemPassword $PASSWORD -sysmanPassword $PASSWORD -dbsnmpPassword $PASSWORD -emConfiguration LOCAL -storageType ASM -diskGroupName $ASMGROUPNAME -datafileJarLocation $ORACLE_HOME/assistants/dbca/templates -nodeinfo $NODE1,$NODE2 -characterset WE8ISO8859P1 -obfuscatedPasswords false -sampleSchema false -oratabLocation /etc/oratab
The following will create a ASM instance & 1 diskgroup (run as the ASM/Oracle user)
$ORA_ASM_HOME/bin/dbca -silent -configureASM -gdbName NO -sid NO -emConfiguration NONE -diskList $ASM_DISKS -diskGroupName $ASMGROUPNAME -nodeinfo $NODE1,$NODE2 -obfuscatedPasswords false -oratabLocation /etc/oratab -asmSysPassword $PASSWORD -redundancy $ASMREDUNDANCY
where ASM_DISKS = '/dev/sda1,/dev/sdb1' and ASMREDUNDANCY='NORMAL'
Can RMAN backup Oracle Real Application Cluster databases?
Absolutely. RMAN can be configured to connect to all nodes within the cluster to parallelize the backup of the database files and archive logs. If files need to be restored, using set AUTOLOCATE ON alerts RMAN to search for backed up files and archive logs on all nodes.
I am receiving an ORA-29740 error. What should I do?
This error can occur when problems are detected on the cluster:
Error: ORA-29740 (ORA-29740)
Text: evicted by member %s, group incarnation %s
---------------------------------------------------------------------------
Cause: This member was evicted from the group by another member of the
cluster database for one of several reasons, which may include a
communications error in the cluster, failure to issue a heartbeat
to the control file, etc.
Action: Check the trace files of other active instances in the cluster
group for indications of errors that caused a reconfiguration.
For more information on troubleshooting this error, see the following note:
Note: 219361.1 Troubleshooting ORA-29740 in a RAC Environment
Does Oracle support rolling upgrades in a cluster?
This answer is for clusters running the Oracle stack. If 3rd party vendor clusterware in included, you need to check with the vendor about their support of a rolling upgrade.
By a rolling upgrade, we mean upgrading software (Oracle Database, Oracle Clusterware, ASM or the OS itself) while the cluster is operational by shutting down a node, upgrading the software on that node, and then reintegrating it into the cluster, and so forth one node at a time until all the nodes in the cluster are at the new software level.
For the Oracle Database software, it is possible only for certain single patches that are marked as rolling upgrade compatible. Most Bundle patches and Critical Patch Updates (CPU) are rolling upgradeable. Patchsets and DB version (10g to 11g) changes are not supported in a rolling fashion, one reason that this may be impossible is that across major releases, there may be incompatible versions of the system tablespace, for example. To upgrade these in a rolling fashion one will need to use a logical standby with Oracle Database 10g or 11g, see Note: 300479.1 for details.
Read the MAA Best Practice on Rolling Database Upgrades using Data Guard SQL Apply or with Oracle RAC 11g, Rolling Database Upgrades for Physical Standby Databases using Transient Logical Standby 11g
The Oracle Clusterware software always fully supports rolling upgrades, while the ASM software is rolling upgradeable at version 11.1.0.6 and beyond.
For Oracle Database 11g Release 2, Oracle Clusterware and ASM binaries are combined into a single ORACLE_HOME called the grid infrastructure home. This home fully supports rolling upgrades for patches, bundles, patchsets and releases. (If you are upgrading ASM from Oracle Database 10g to 11g Release 2, you will not be able to upgrade ASM in a rolling fashion.)
The Oracle Clusterware and Oracle Real Application Clusters both support rolling upgrades of the OS software when the version of the Oracle Database is certified on both releases of the OS (and the OS is the same, no Linux and Windows or AIX and Solaris, or 32 and 64 bit etc.). This can apply a patch to the operating system, a patchset (such as EL4u4 to EL4u6) or a release (EL4 to EL5).
Stay within a 24 hours of upgrade window and fully test this path as it's not possible for Oracle to test all these different paths and combinations.
I have a 2 node Oracle RAC cluster, if I pull the interconnect on node 1 to simulate failure, why does node 2 reboot?
When Oracle Clusterware recognizes a problem on the interconnect, it will try to keep the largest sub-cluster running. However in a 2 node cluster, we can only keep one node up so the first node that joined the cluster will be the node that stays up and Oracle Clusterware will reboot the other node even if you pulled the cable from the node that stayed up. In the case above, if node 1 was the first node to join the cluster (ie...the first one started), even if you pull the interconnect cable from node 1, node 2 will be rebooted.
Is Oracle Application Server integrated with FAN and FCF?
Yes, For detailed information on the integration with the various releases of Application Server 10g,
http://www.oracle.com/technology/tech/java/newsletter/articles/oc4j_data_sources/oc4j_ds.htm
How do I configure FCF with BPEL so I can use Oracle RAC 10g in the backend?
Note: 372456.1 describes the procedure to set up BPEL with a Oracle RAC 10g Release 1 database.
If you are using SSL, ensure the SSL enable attribute of ONS in opmn.xml file has same value, either true or false, for all OPMN servers in the Farm. To troubleshoot OPMN at the application server level, look at appendix A in Oracle® Process Manager and Notification Server Administrator's Guide.
Where can I find more information on cluster_interconnects?
Oracle 9i: Note: 183340.1
Oracle 10g & 11g: Note: 787420.1
Solaris IPMP specific: Note: 368464.1
Links to documentation:
Oracle 9 to 11g: Note: 151051.1
As well as: Oracle Real Application Clusters Administration and Deployment Guide: 11g Release 1 and 10g Release 2
How does OCR mirror work? What happens if my OCR is lost/corrupt?
OCR is the Oracle Cluster Registry, it holds all the cluster related information such as instances, services. The OCR file format is binary and starting with 10.2 it is possible to mirror it. Location of file(s) is located in: /etc/oracle/ocr.loc in ocrconfig_loc and ocrmirrorconfig_loc variables.
Obviously if you only have one copy of the OCR and it is lost or corrupt then you must restore a recent backup, see ocrconfig utility for details, specifically -showbackup and -restore flags. Until a valid backup is restored the Oracle Clusterware will not startup due to the corrupt/missing OCR file.
The interesting discussion is what happens if you have the OCR mirrored and one of the copies gets corrupt? You would expect that everything will continue to work seemlessly. Well.. Almost.. The real answer depends on when the corruption takes place.
If the corruption happens while the Oracle Clusterware stack is up and running, then the corruption will be tolerated and the Oracle Clusterware will continue to funtion without interruptions. Despite the corrupt copy. DBA is advised to repair this hardware/software problem that prevent OCR from accessing the device as soon as possible; alternatively, DBA can replace the failed device with another healthy device using the ocrconfig utility with -replace flag.
If however the corruption happens while the Oracle Clusterware stack is down, then it will not be possible to start it up until the failed device becomes online again or some administrative action using ocrconfig utility with -overwrite flag is taken. When the Clusteware attempts to start you will see messages similar to:
total id sets (1), 1st set (1669906634,1958222370), 2nd set (0,0) my votes (1), total votes (2)
2006-07-12 10:53:54.301: [OCRRAW][1210108256]proprioini:disk 0 (/dev/raw/raw1) doesn't have enough votes (1,2)
2006-07-12 10:53:54.301: [OCRRAW][1210108256]proprseterror: Error in accessing physical storage [26]
This is because the software can't determin which OCR copy is the valid one. In the above example one of the OCR mirrors was lost while the Oracle Clusterware was down. There are 3 ways to fix this failure:
a) Fix whatever problem (hardware/software?) that prevent OCR from accessing the device.
b) Issue "ocrconfig -overwrite" on any one of the nodes in the cluster. This command will overwrite the vote check built into OCR when it starts up. Basically, if OCR device is configured with mirror, OCR assign each device with one vote. The rule is to have more than 50% of total vote (quorum) in order to safely make sure the available devices contain the latest data. In 2-way mirroring, the total vote count is 2 so it requires 2 votes to achieve the quorum. In the example above there isn't enough vote to start if only one device with one vote is available. (In the earlier example, while OCR is running when the device is down, OCR assign 2 vote to the surviving device and that is why this surviving device now with two votes can start after the cluster is down). See warning below
c) This method is not recommend to be performed by customers. It is possible to manually modify ocr.loc to delete the failed device and restart the cluster. OCR won't do the vote check if the mirror is not configured. See warning below
EXTREME CAUTION should be excersized if chosing option b or c above since data loss can occur if the wrong file is manipulated, please contact Oracle Support for assistance before proceeding.
If I change my cluster configuration, do I need to update the ONS configuration on my middle tier?
For the best availability and to ensure the application receives all FAN events, yes, you should update the configuration. To a certain degree, ONS will discover nodes. ONS runs on each node in the cluster and is aware of all other nodes in the cluster. As long as when ONS on the middle tier can find at least one node in the cluster when it starts, it will find the rest of the nodes. In the case where the only node up is the new node in the cluster when the middle tier starts, the middle tier will not find the cluster.
Why do we have a Virtual IP (VIP) in Oracle RAC 10g or 11g? Why does it just return a dead connection when its primary node fails?
The goal is application availability.
When a node fails, the VIP associated with it is automatically failed over to some other node. When this occurs, the following things happen.
(1) VIP detects public network failure which generates a FAN event.
(2) the new node re-arps the world indicating a new MAC address for the IP.
(3) connected clients subscribing to FAN immediately receive ORA-3113 error or equivalent. Those not subscribing to FAN will eventually time out.
(4) New connection requests rapidly traverse the tnsnames.ora address list skipping over the dead nodes, instead of having to wait on TCP-IP timeouts
Without using VIPs or FAN, clients connected to a node that died will often wait for a TCP timeout period (which can be up to 10 min) before getting an error.
As a result, you don't really have a good HA solution without using VIPs and FAN. The easiest way to use FAN is to use an integrated client with Fast Connection Failover (FCF) such as JDBC, OCI, or ODP.NET.
What do the VIP resources do once they detect a node has failed/gone down? Are the VIPs automatically acquired, and published, or is manual intervention required? Are VIPs mandatory?
With Oracle RAC 10g or higher, each node requires a VIP. With Oracle RAC 11g Release 2, 3 additional SCAN vips are required for the cluster. When a node fails, the VIP associated with the failed node is automatically failed over to one of the other nodes in the cluster. When this occurs, two things happen:
The new node re-arps the world indicating a new MAC address for this IP address. For directly connected clients, this usually causes them to see errors on their connections to the old address;
Subsequent packets sent to the VIP go to the new node, which will send error RST packets back to the clients. This results in the clients getting errors immediately.
In the case of existing SQL conenctions, errors will typically be in the form of ORA-3113 errors, while a new connection using an address list will select the next entry in the list. Without using VIPs, clients connected to a node that died will often wait for a TCP/IP timeout period before getting an error. This can be as long as 10 minutes or more. As a result, you don't really have a good HA solution without using VIPs.
With Oracle RAC 11g Release 2, you can delegate the management of the VIPs to the cluster. If you do this, the Grid Naming Service (part of the Oracle Clusterware) will automatically allocated and manage all VIPs in the cluster. This requires a DHCP service on the public network.
If I use Services with Oracle RAC, do I still need to set up Load Balancing ?
Yes, Services allow you granular definition of workload and the DBA can dynamically define which instances provide the service. Connection Load Balancing (provided by Oracle Net Services) still needs to be set up to allow the user connections to be balanced across all instances providing a service. With Oracle RAC 10g Release 2 or higher, set the CLB_GOAL on service to define the type of load balancing you want, SHORT for short lived connections (IE connection pool) or LONG (default) for applciations that have connections active for long periods (IE Oracle Forms applicaiton).
How can a customer mask the change in their clustered database configuration from their client or application? (I.E. So I do not have to change the connection string when I add a node to the Oracle RAC database)
The combination of Server Side load balancing and Services allows you to easily mask cluster database configuration changes. As long as all instances register with all listeners (use the LOCAL_LISTENER and REMOTE_LISTENER parameters), server side load balancing will allow clients to connect to the service on currently available instances at connect time.
The load balancing advisory (setting a goal on the service) will give advice as to how many connections to send to each instance currently providing a service. When a service is enabled on an instance, as long as the instance registers with the listeners, the clients can start getting connections to the service and the load balancing advisory will include that instance is its advice.
With Oracle RAC 11g Release 2, the Single Client Access Name (SCAN) provides a single name to be put in the client connection string (as the address). Clients using SCAN never have to change even if the cluster configuration changes such as adding nodes.
After executing DBMS_SERVICE.START_SERVICE, the service resource remains in an OFFLINE status when I display the cluster resource status. Is that expected behaviour ?
YES this is expected behaviour. Unfortunately, the DBMS_SERVICE.START_SERVICE does not update the clusterware until 11g Release 2. You should use srvctl start service -d dbname then you should see it come online.
Note: With Oracle RAC 11g Release 2, the cluster resource for a Service, contains the values for all the attributes of a service. Oracle Clusterware will update the database with its values when it starts a service. In order to save modifications across restarts, all service modifications should be made with srvctl (or Oracle Enterprise Manager).
What are my options for load balancing with Oracle RAC? Why do I get an uneven number of connections on my instances?
All the types of load balancing available currently (9i-10g) occur at connect time.
This means that it is very important how one balances connections and what these connections do on a long term basis.
Since establishing connections can be very expensive for your application, it is good programming practice to connect once and stay connected. This means one needs to be careful as to what option one uses. Oracle Net Services provides load balancing or you can use external methods such as hardware based or clusterware solutions.
The following options exist prior to Oracle RAC 10g Release 2 (for 10g Release 2 see Load Balancing Advisory):
Random
Either client side load balancing or hardware based methods will randomize the connections to the instances.
On the negative side this method is unaware of load on the connections or even if they are up meaning they might cause waits on TCP/IP timeouts.
Load Based
Server side load balancing (by the listener) redirects connections by default depending on the RunQ length of each of the instances. This is great for short lived connections. Terrible for persistent connections or login storms. Do not use this method for connections from connection pools or applicaton servers
Session Based
Server side load balancing can also be used to balance the number of connections to each instance. Session count balancing is method used when you set a listener parameter, prefer_least_loaded_node_listener-name=off. Note listener name is the actual name of the listener which is different on each node in your cluster and by default is listener_nodename.
Session based load balancing takes into account the number of sessions connected to each node and then distributes the connections to balance the number of sessions across the different nodes.
What do I do if I am getting handshake failed messages in my ONS.LOG file every minute?
For Example: The client gets this error message in Production in the ons.log file every minute or so: 06/11/10 10:11:14 [2] Connection 0,129.86.186.58,6200 SSL handshake failed 06/11/10 10:11:14 [2] Handshake for 0,129.86.186.58,6200: nz error = 29049 interval = 0 (180 max) These annoying messages in ons.log are telling you that you have a configuration mismatch for ONS somewhere in the farm. Oracle RAC has its own ONS server for which SSL is disabled by default. You must either enable SSL for Oracle RAC ONS, or disable it for OID ONS(OPMN). You need to create a wallet for each Oracle RAC ONS server, or copy one of the wallets from OPMN on the OID instances.
In ons.conf you need to specify the wallet file and password:
walletfile=
walletpassword=
ONS only uses SSL between servers, and so ONS clients will not be affected. You specify the wallet password when you create the wallet. If you copy a wallet from an OPMN instance, then use the same password configured in opmn.xml. If there is no wallet password configured in opmn.xml, then you don't need to specify a wallet password in ons.conf either.
What should I do to make my Oracle RAC deployment highly available?
Customers often deploy Oracle Real Application Clusters (RAC) to provide a highly available infrastructure for their mission critical applications. Oracle RAC removes the server as a single point of failure. Load balancing your workload across many servers’ along with fast recovery from failures means that the loss of any one server should have little or no impact on the end user of the application. The level of impact to the end user depends on how well the application has been written to mask failure. If an outage occurs on an Oracle RAC instance, the ideal situation would be that the failover time + transaction response time to be less then the maximum acceptable response time. Oracle RAC has many features that customers can take advantage of to mask failures from the end user however it requires more work than just installing Oracle RAC. To the application user, the availability metric that means the most is the response time for their transaction. This is the end-to-end response time which means all layers must be available and performing to a defined standard for the agreed times.
If you are deploying Oracle RAC and require high availability, you must make the entire infrastructure of the application highly available. This requires detailed planning to ensure there are no single points of failure throughout the infrastructure. Oracle Clusterware is constantly monitoring any process that it under its control, which includes all the Oracle software such as the Oracle instance, listener, etc. Oracle Clusterware has been programmed to recover from failures, which occur for the Oracle processes. In order to do it’s monitoring and recovery, various system activities happen on a regular basis such as user authentication, sudo, and hostname resolution. In order for the cluster to be highly available, it must be able to perform these activities at all times. For example, if you choose to use the Lightweight Directory Access Protocol (LDAP) for authentication, then you must make the LDAP server highly available as well as the network connecting the users, application, database and LDAP server. If the database is up but the users cannot connect to the database because the LDAP server is not accessible, then the entire system is down in the eyes of your users. When using external authentication such as LDAP or NIS (Network Information Service), a public network failure will cause failures within the cluster. Oracle recommends that the hostname, vip, and interconnect are defined in the /etc/hosts file on all nodes in the cluster.
During the testing of the Oracle RAC implementation, you should include a destructive testing phase. This is a systematic set of tests of your configuration to ensure that 1) you know what to expect if the failure occurs and how to recover from it and 2) that the system behaves as expected during the failure. This is a good time to review operating procedures and document recovery procedures. Destructive testing should include tests such as node failure, instance failure, public network failure, interconnect failures, storage failure, storage network failure, voting disk failure, loss of an OCR, and loss of ASM.
Using features of Oracle Real Application Clusters and Oracle Clients including Fast Application Notification (FAN), Fast Connection Failover (FCF), Oracle Net Service Connection Load Balancing, and the Load Balancing Advisory, applications can mask most failures and provide a very highly available application. For details on implementing best practices, see the MAA document Client Failover Best Practices for Highly Available Oracle Databases and the Oracle RAC Administration and Deployment Guide.
Can our Oracle RAC 10g VIP fail over from NIC to NIC as well as from node to node ?
Yes, the Oracle RAC 10g VIP implementation is capable from failing over within a node from NIC to NIC and back if the failed NIC is back online again, and also we fail over between nodes. The NIC to NIC failover is fully redundant if redundant switches are installed.
Is there a way to provide or configure HA for the interconnect using Infiniband on AIX ?
The HA support will be with VIPA configured over two separate IB interfaces. The two interfaces can either be two ports on one adapter (not ideal HA) or two ports from different adapters. This VIPA configuration is different from the "AIX Etherchannel" configuration. "AIX Etherchannel" is not supported with Infiniband;
I am using shared services which the following set in init.ora SQL> show parameters dispatchers=(protocol=TCP)(listener=listen ers_nl01)(con=500)(serv=oltp). I stopped my service with srvctl stop service but it is still registered with the listener and accepting connections. Is this expected?
YES. This is by design of dispatchers which are part of Oracle Net Services. If you specify the service attribute of the dispatchers init.ora parameter, the service specified cannot be managed by the dba.
Is it possible to use SVRCTL start database with a user account other than oracle ( that is other than the owner of the oracle software)?
YES. When you create a RAC db as a user different than the home/software owner (oracle) user, the db creation assistant would set the correct permissions/ACLs on the CRS resources that control the db/instances etc, assuming that you had setup group membership for this user to the dba group of the home (find it using oracle_home/bin/osdbagrp) and also part of the crs home owners primary group (usually oinstall) and there was group write permission on the oracle_home.
With three primary load balancing options (client-side connect-time LB, server-side connect-time LB, and the runtime connection load balancing) Is it fair to say Runtime Connection Load Balancing is the only option to leverage FAN up/down events?
No. The listener is a subscriber to all FAN events (both from the load balancing advisory and the HA events). Therefore server side connection load balancing leverages FAN HA events as well as laod balancing advisory events.
With the Oracle JDBC driver 10g Release 2, if you enable Fast Connection Failover, you also enable Runtime Connection Load Balancing (one knob for both).
What is Server-side Transparent Application Failover (TAF) and how do I use it?
Oracle Database 10g Release 2, introduces server-side TAF when using services. After you create a service, you can use the dbms_service.modify_service pl/sql procedure to define the TAF policy for the service. Only the basic method is supported. Note this is different than the TAF policy (traditional client TAF) that is supported by srvctl and EM Services page. If your service has a server side TAF policy defined, then you do not have to encode TAF on the client connection string. If the instance where a client is connected, fails, then the connection will be failed over to another instance in the cluster that is supporting the service. All restrictions of TAF still apply.
NOTE: both the client and server must be 10.2 and aq_ha_notifications must be set to true for the service.
Sample code to modify service:
execute dbms_service.modify_service (service_name => 'gl.us.oracle.com' -
, aq_ha_notifications => true -
, failover_method => dbms_service.failover_method_basic -
, failover_type => dbms_service.failover_type_select -
, failover_retries => 180 -
, failover_delay => 5 -
, clb_goal => dbms_service.clb_goal_long);
What is CLB_GOAL and how should I set it?
CLB_GOAL is the connection load balancing goal for a service. There are 2 options, CLB_GOAL_SHORT and CLB_GOAL_LONG (default).
Long is for applications that have long-lived connections. This is typical for connection pools and SQL*Forms sessions. Long is the default connection load balancing goal.
Short is for applications that have short-lived connections.
The GOAL for a service can be set with EM or DBMS_SERVICE.
Note: You must still configure load balancing with Oracle Net Services
What does the Virtual IP service do? I understand it is for failover but do we need a separate network card? Can we use the existing private/public cards? What would happen if we used the public ip?
The 10g Virtual IP Address (VIP) exists on every RAC node for public network communication. All client communication should use the VIPs in their TNS connection descriptions. The TNS ADDRESS_LIST entry should direct clienst to VIPs rather than using hostnames. During normal runtime, the behaviour is the same as hostnames, however when the node goes down or is shutdown the VIP is hosted elsewhere on the cluster, and does not accept connection requests. This results in a silent TCP/IP error and the client fails immediately to the next TNS address. If the network interface fails within the node, the VIP can be configured to use alternate interfaces in the same node. The VIP must use the public interface cards. There is no requirement to purchase additional public interface cards (unless you want to take advantage of within-node card failover.)
I want to configure a secure environment for ONS so have added a Wallet however I am seeing errors (SSL handshake failed) after adding the wallet?
Remember that if you enable SSL for one instance of ONS, you must enable SSL for all instances with ONS (including any AS instances running OPMN).
The error message in this case showed that SSL is enabled for the local ONS server, but the SSL handshake is failing when another ONS or OPMN server attempts to connect to it, indicating that the remote server does not have SSL enabled (or has an incompatible wallet configured).
Do I need to install the ONS on all my mid-tier serves in order to enable JDBC Fast Connection Failover (FCF)?
With 10g Release 1, the middle tier must have ONS running (started by same users as application). ONS is not included on the Client CD however is is part of the Oracle Database 10g cd.
With 10g Release 2 or later, they do not need to install the ons on the middle tier. The JDBC driver allows the use of remote ONS (ie uses the ONS running in the RAC cluster) . Just use the datasource parameter ods.setONSConfiguration("nodes=racnode1:4200,racnode2.:4200");
Will FAN/FCF work with the default database service?
No. If you want the advanced features of RAC provided by FAN and FCF, then create a cluster managed service for your application. Use the Clustered Managed Services Page in Enterprise Manager DBControl to do this.
Will FAN work with SQLPlus?
Yes with Oracle RAC 11g, you can specify the -F (FAILOVER) option. This enables SQL*Plus to interact with the OCI failover mode in a Real Application Cluster (RAC) environment. In this mode a service or instance failure is transparently handled with transaction status messages if applicable.
Why am I seeing the following warnings in my listener.log for my RAC 10g environment?
WARNING: Subscription for node down event still pending
This message indicates that the listener was not able to subscribe to the ONS events which it uses to do the connection load balancing. This is most likely due to starting the listener using lsnrctl from the database home. When you start the listener using lsnrctl, make sure you have set the environment variable ORACLE_CONFIG_HOME = {Oracle Clusterware HOME}, also set it in racgwrap in the $ORACLE_HOME/bin for the database.
Can I use the 10.2 JDBC driver with 10.1 database for FCF?
Yes with the patch for Bug 5657975 for 10.2.0.3,the 10.2 JDBC driver will work with a 10.1 database. The fix will be part of the 10.2.0.4 patchset. If you do not have the patch then using FCF, use the 10.2 JDBC driver with 10.2 database. If database is 10.1, use 10.1 JDBC driver.
What clients provide integration with FAN through FCF?
With Oracle Database 10g Release 1, JDBC clients (both thick and thin driver) are integrated with FAN by providing FCF. With Oracle Database 10g Release 2, we have added ODP.NET and OCI. Other applications can integrate with FAN by using the API to subscribe to the FAN events.
Note: If you are using a 3rd party application server, then you can only use FCF if you use the Oracle driver and except for OCI, its connection pool. If you are using the connection pool of the 3rd Party Application Server, then you do not get FCF. Your customer can subscribe directly to FAN events however that is a development project for the customer. See the white paper Workload Management with Oracle RAC 10g on OTN
Can I use TAF and FAN/FCF?
With Oracle Database 10g Release 1, NO. With Oracle Database 10g Release 2, the answer is YES for OCI and ODP.NET, it is recommended. For JDBC, you should not use TAF and FCF even with the Thick JDBC driver.
How does the datasource properties initialLimit, minLimit, and maxLimit affect Fast Connection Failover processing with JDBC?
The initialLimit property on the Implicit Connection Cache is effective only when the cache is first created. For example, if the initialLimit is set to 10, you'll have 10 connections pre-created and available when the conn cache is first created. Pls don't be confused between minLimit and initialLimit. The current behavior is that after a DOWN event and the affected connections are cleaned up, it is possible for the number of connections in the cache to be lower than minLimit.
An UP event is processed for both (a) new instance joins, as well as (b) down followed by an instance UP. This has no relevance to initialLimit, or even minLimit. When a UP event comes into our jdbc Implicit Connection Cache, we will create some new connections. Assuming you have your listener load balancing set up properly, then those connections should go to the instance that was just started. When your application does a get connection to the pool, it will be given an idle connection, if you are running 10.2 and have the load balancing advisory turned on for the service, we will allocate the session based on the defined goal to provide the best service level
MaxLimit, when set, defines the upper boundary limit for the connection cache. By default, maxLimit is unbounded - your database sets the limit.
Will FAN/OCI work with Instant Client?
Yes, FAN/OCI will work with Instant Client. Both client and server must be Oracle Database 10g Release 2.
What type of callbacks are supported with OCI when using FAN/FCF?
There are two separate callbacks supported. The HA Events (FAN) callback is called when an event occurs. When a down event occurs, for example, you can clean up a custom connection pool. i.e. purge stale connections. When the failover occurs, the TAF callback is invoked. At failover time you can customize the newly created database session. Both FAN and TAF are client-side callbacks. FAN also has a separate server side callout that should not be confused with the OCI client callback.
Does FCF for OCI react to FAN HA UP events?
OCI does not perform any implicit actions on an up event, however if a HA event callback is present, it is invoked. You can take any required action at that time.
Can I use FAN/OCI with Pro*C?
Since Pro*C (sqllib) is built on top of OCI, it should support HA events. You need to precompile the application with the option EVENTS=TRUE, make sure you link the application with a thread library. The database connection must use a Service that has been enabled for AQ events. Use dbms_service.modify_service to enable the service for events (aq_ha_notifications => true) or use the EM Cluster Database Services page.
Do I have to link my OCI application with a thread library? Why?
YES, you must link the application to a threads library. This is required because the AQ notifications occur asynchronously, over an implicitly spawned thread.
I am seeing the wait events 'ges remote message', 'gcs remote message', and/or 'gcs for action'. What should I do about these?
These are idle wait events and can be safetly ignored. The 'ges remote message' might show up in a 9.0.1 statspack report as one of the top wait events. To have this wait event not show up you can add this event to the PERFSTAT.STATS$IDLE_EVENT table so that it is not listed in Statspack reports.
What are the changes in memory requirements from moving from single instance to RAC?
If you are keeping the workload requirements per instance the same, then about 10% more buffer cache and 15% more shared pool is needed. The additional memory requirement is due to data structures for coherency management. The values are heuristic and are mostly upper bounds. Actual esource usage can be monitored by querying current and maximum columns for the gcs resource/locks and ges resource/locks entries in V$RESOURCE_LIMIT.
But in general, please take into consideration that memory requirements per instance are reduced when the same user population is distributed over multiple nodes. In this case:
Assuming the same user population N number of nodes M buffer cache for a single system then
(M / N) + ((M / N )*0.10) [ + extra memory to compensate for failed-over users ]
Thus for example with a M=2G & N=2 & no extra memory for failed-over users
=( 2G / 2 ) + (( 2G / 2 )) *0.10
=1G + 100M
What are my options for setting the Load Balancing Advisory GOAL on a Service?
The load balancing advisory is enabled by setting the GOAL on your service either through PL/SQL DBMS_SERVICE package or EM DBControl Clustered Database Services page. There are 3 options for GOAL:
None - Default setting, turn off advisory
THROUGHPUT - Work requests are directed based on throughput. This should be used when the work in a service completes at homogenous rates. An example is a trading system where work requests are similar lengths.
SERVICE_TIME - Work requests are directed based on response time. This should be used when the work in a service completes at various rates. An example is as internet shopping system where work requests are various lengths
Note: If using GOAL, you should set CLB_GOAL=SHORT
Will adding a new instance to my Oracle RAC database (new node to the cluster) allow me to scale the workload?
YES! Oracle RAC allows you to dynamically scale out your workload by adding another node to the cluster. You must remember that adding more work to the database means that in addition to the CPU and Memory that the new node brings, you will have to ensure that your I/O subsystem can support the additional I/O requirements. In an Oracle RAC environment, you need to look at the total I/O across all instances in the cluster.
FAQ 9393
How do I change my Veritas SF RAC installation to use UDP instead of LLT?
Using UDP with Veritas Clusterware and Oracle RAC 10g seems to require an exception from Veritas so this may be something you should check with them.
To make it easier for customers to convert their LLT environments to UPD, Oracle has created Patch 6846006 on 10.2.0.3 which contains the libraries that were overwritten by the Veritas installation (IE those mentioned above). Converting from specialized protocols to UDP requires a relink after the Oracle libraries have been restored. This needs a complete cluster shutdown and cannot be accomplished in a rolling fashion.
NOTE: Oracle RAC 11g will not support LLT for interconnect.
Can I have different servers in my Oracle RAC? Can they be from different vendors? Can they be different sizes?
Oracle Real Application Clusters (RAC) requires all the nodes to run the same Operating System binary in a cluster (IE All nodes must be Windows 2008 or all nodes must be OEL 4). All nodes must be the same architecture (I.E. All nodes must be either 32 bit or all nodes must be 64 bit or all nodes must be HP-UX PARISC since you cannot mix PARISC with Itanium).
Oracle RAC does support a cluster with nodes that have different hardware configurations. An example is a cluster with 3 nodes with 4 CPUs and another node with 6 CPUs. This can easily occur when adding a new node after the cluster has been in production for a while. For this type of configuration, customers must consider some additional features to get the optimal cluster performance. The servers used in the cluster can be from different vendors; this is fully supported as long as they run the same binaries. Since many customers implement Oracle RAC for high availability, you must make sure that your hardware vendor will support the configuration. If you have a failure, will you get support for the hardware configuration?
The installation of Oracle Clusterware expects the network interface to be the same name on all nodes in the cluster. If you are using different hardware, you may need to work with your operating system vendor to make sure the network interface names are the same name on all nodes (IE eth0). Customers implementing uneven cluster configurations need to consider how they will balance the workload across the cluster. Some customers have chosen to manually assign different workloads to different nodes. This can be done using database services however it is often difficult to predict workloads and the system cannot dynamically react to changes in workload. Changes to workload require the DBA to modify the service. You will also need to consider how you will survive failures in the cluster. Will the service levels be maintained if the larger node in the cluster fails? Especially in a small cluster, the impact of losing a node could impact the ability to continue processing the application workload.
The impact of the different sized nodes depends on how much difference there is in the size. If there is a large difference between the nodes in terms of memory and CPU size, than the "bigger" nodes will attract more load, obviously, and in the case of failure the "smaller" node(s) will become overpowered. In such a case, static routing of workload via services e.g. batch and certain services, which can be suspended/stopped if the large node fails and the cluster has significantly reduced capacity, may be advisable. The general recommendation is that the nodes should be sized in such a way that the aggregated peak load of the large node(s) can be absorbed by the smaller node(s), i.e. smaller node should have sufficient capacity to run the essential services alone. Another option is to add another small node to the cluster on demand in case that the large one fails.
It should also be noted especially if there is a large difference between the sizes of the nodes, the small nodes can slow down the larger node. This could be critical one if the smaller node is very busy and must serve data to the large node.
To help balance workload across a cluster, Oracle RAC 10g Release 2 and above provides the Load Balancing Advisory (LBA). The load balancing advisory runs in an Oracle RAC database and monitors the work executed by the service on all instances where the service is active in the cluster. The LBA provides recommendations to the subscribed clients about the state of the service and where the client should direct connection requests. Setting the GOAL on the service activates the load balancing advisory. Clients that can utilize the load balancing advisory are Oracle JDBC Implicit Connection Cache, Oracle Universal Connection Pool for Java, Oracle Call Interface Session Pool, ODP.NET Connection Pool, and Oracle Net Services Connection Manager. The Oracle Listener also uses the Load Balancing Advisory if CLB_GOAL parameter is set to SHORT (recommended Best Practice if using an integrated Oracle Client mentioned here). If CLB_GOAL is set to LONG (default), the Listener will load balance the number of sessions for the service across the instances where the service is available. See the Oracle Real Application Clusters Administration and Deployment Guide for details on implementing services and the various parameter settings.
What do I do if I see GC CR BLOCK LOST in my top 5 Timed Events in my AWR Report?
You should never see this or BLOCK RETRY events. This is most likely due to a fault in your interconnect network. Work with your system administrator or/and network administrator to find the fault. Check netstat -s
Ip:
84884742 total packets received
1201 fragments dropped after timeout
3384 packet reassembles failed
You do not want to see fragments dropped or packet reassemblies failed.
ifconfig –a:
eth0 Link encap:Ethernet HWaddr 00:0B:DB:4B:A2:04
inet addr:130.35.25.110 Bcast:130.35.27.255 Mask:255.255.252.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:21721236 errors:135 dropped:0 overruns:0 frame:95
TX packets:273120 errors:0 dropped:0 overruns:0 carrier:0
You do not want to see high number of errors.
A customer is currently using RAC in a 2 node environment. How should one review the ability to scale out to 4, 6, 8 or even more nodes? What should the requirements of a scale out test?
Once a customer is using RAC on a two node cluster and want to see how far they can actually scale it, the following are some handy tips to follow:
1. Ensure they are using a real enough workload that it does not have false bottlenecks.
2. Have tuned the application so it is reasonable scalable on their current RAC environment.
3. Make sure you are measuring a valid scalability measure. This should either be doing very large batch jobs quicker (via parallelism) or being able to support a greater number of short transactions in a shorter time.
4. Actual scalability will vary for each application and its bottlenecks. Thus the request to do the above items. You would see similar scalability if scaling up on a SMP.
5. For failover, you should see what happens if you lose a node. If you have 2 nodes, you lose half your power and really get into trouble or have lots of extra capacity.
6. Measuring that load balacing is working properly. Make sure you are using RCLB and a FAN aware connection pool.
7. Your customer should also testing using DB Services.
8. Get familiar w/ EM GC to manage a cluster and help eliminate a lot of the complexity of many of the nodes.
9. Why stop at 6 nodes? A maximum of 3 way messaging ensure RAC can scale much, much further.
What is the Load Balancing Advisory?
To assist in the balancing of application workload across designated resources, Oracle Database 10g Release 2 provides the Load Balancing Advisory. This Advisory monitors the current workload activity across the cluster and for each instance where a service is active; it provides a percentage value of how much of the total workload should be sent to this instance as well as service quality flag. The feedback is provided as an entry in the Automatic Workload Repository and a FAN event is published. The easiest way for an application to take advantage of the load balancing advisory, is to enable Runtime Connection Load Balancing with an integrated client.
How do I enable the load balancing advisory?
The load balancing advisory requires the use of services and Oracle Net connection load balancing.
To enable it, on the server: set a goal (service_time or throughput, and set CLB_GOAL=SHORT ) on your service.
For client, you must be using the connection pool.
For JDBC, enable the datasource parameter FastConnectionFailoverEnabled.
For ODP.NET enable the datasource parameter Load Balancing=true.
How can I validate the scalability of my shared storage? (Tightly related to RAC / Application scalability)
Storage vendors tend to focus their sales pitch mainly on the storage unit's capacity in Terabytes (1000 GB) or Petabytes (1000 TB), however for RAC scalability it's critical to also look at the storage unit's ability to process I/O's per second (throughput) in a scalable fashion, specifically from multiple sources (nodes). If that criteria is not met, RAC / Application scalability most probably will suffer, as it partially depends on storage scalability as well as a solid and capable interconnect (for network traffice between nodes).
Storage vendors may sometimes discourage such testing, boasting about their amazing front or backend battery backed memory caches that "eliminate" all I/O bottlenecks. This is all great, and you should take advantage of such caches as much as possible... however, there is no substitute to a a real world test, you may uncover that the HBA (Host Buss Adapater) firmware or the driver versions are outdated (before you claim poor RAC / Application scalability issues).
It is highly recommended to test this storage scalability early on so that expectations are set accordingly. On Linux there is a freely available tool released on OTN called ORION (Oracle I/O test tool) which simulates Oracle I/O.
On other Unix platforms (as well as Linux) one can use IOzone, if prebuilt binary not available you should build from source, make sure to use version 3.271 or later and if testing raw/block devices add the "-I" flag.
In a basic read test you will try to demonstrate that a certain IO throughput can be maintained as nodes are added. Try to simulate your database io patterns as much as possible, i.e. blocksize, number of simultaneous readers, rates, etc.
For example, on a 4 node cluster, from node 1 you measure 20MB/sec, then you start a read stream on node 2 and see another 20MB/sec while the first node shows no decrease. You then run another stream on node 3 and get another 20MB/sec, in the end you run 4 streams on 4 nodes, and get an aggregated 80MB/sec or close to that. This will prove that the shared storage is scalable. Obviously if you see poor scalability in this phase, that will be carried over and be observed or interperted as poor RAC / Application scalability.
In many cases RAC / Application scalability is at blame for no real reason, that is, the underlying IO subsystem is not scalable.
How many nodes are supported in a RAC Database?
With 10g Release 2, we support 100 nodes in a cluster using Oracle Clusterware, and 100 instances in a RAC database. Currently DBCA has a bug where it will not go beyond 63 instances. There is also a documentation bug for the max-instances parameter. With 10g Release 1 the Maximum is 63. In 9i it is platform specific due to the different clusterware support by vendors. See the platform specific FAQ for 9i.
How do I measure the bandwidth utilization of my NIC or my interconnect?
One simple/quick and not very recommended way is to look at output of "ifconfig eth0" and compare values of "RX bytes" and "TX bytes" over time this will show _average_ usage per period of time.
A more reliable, interactive way on Linux is to use the iptraf utility or the prebuilt rpms from redhat or Novell (SuSE), another option on Linux is Netperf . On other Unix platforms: "snoop -S -tr -s 64 -d hme0", AIX's topaz can show that as well.. Try to look for the peak (not average) usage and see if that is acceptably fast.
Remember that NIC bandwidth is measured in Mbps or Gbps (which is BITS per second) and output from above utilities can sometimes come in BYTES per second, so for comparison, do proper conversion (divide bps value by 8 to get bytes/sec; or, multiple bytes value by 8 to get bps value).
Additionally, you can't expect a network device to run at full capacity with 100% efficiency, due to concurrency, collisions and retransmits that happens more frequently as the utilization gets higher. If you are reaching high levels consider a faster interconnect or NIC bonding (multiple NICs all servicing the same IP address).
Finally, above is measuring bandwidth utilization (how much), not latency (how fast) of the interconnect, you may still be suffering from high latency connection (slow link) even though there is plenty of bandwidth to spare. Most experts agree that low latency is by far more important than a high bandwidth with respect to specifications of the private interconnect in RAC. Latency is best measured by the actual user of the network link (RAC in this case), review statspack for stats on latency. Also, in 10gR2 Grid Control you can view Global Cache Block Access Latency, you can also drill down to the Cluster Cache Coherency page to see the cluster cache coherency metrics for the entire cluster database.
Keep in mind that RAC is using the private interconnect like it was never used before, to synchronize memory regions (SGAs) of multiple nodes (remember, since 9i, entire data blocks are shipped accross the interconnect), if the network is utilized at 50% bandwidth, this means that 50% of the time it is busy and not available to potential users. In this case delays (due to collisions and concurrency) will increase the latency even though the bandwidth might look "reasonable", it's hiding the real issue.
Does Database blocksize or tablespace blocksize affect how the data is passed across the interconnect?
Oracle ships database block buffers, i.e. blocks in a tablespace configured for 16K will result in a 16K data buffer shipped, blocks residing in a tablespace with base block size (8K) will be shipped as base blocks and so on; the data buffers are broken down to packets of MTU sizes.
What is Runtime Connection Load Balancing?
Runtime connection load balancing enables the connection pool to route incoming work requests to the available database connection that will provide it with the best service. This will provide the best service times globally, and routing responds fast to changing conditions in the system. Oracle has implemented runtime connection load balancing with ODP.NET and JDBC connection pools. Runtime Connection Load Balancing is tightly integrated with the automatic workload balancing features introduced with Oracle Database 10g I.E. Services, Automatic Workload Repository, and the new Load Balancing Advisory.
How should I deal with space management? Do I need to set free lists and free list groups?
Manually setting free list groups is a complexity that is no longer required.
We recommend using Automatic Segment Space Management rather than trying to manage space manually. Unless you are migrating from an earlier database version with OPS and have already built and tuned the necessary structures, Automatic Segment Space Management is the preferred approach.
Automatic Segment Space Management is NOT the default, you need to set it.
For more information see:
Note: 180608.1 Automatic Space Segment Management in RAC Environments
I was installing Oracle 9i RAC and my Oracle files did not get copied to the remote node(s). What went wrong?
First make sure the cluster is running and is available on all nodes. You should be able to see all nodes when running an 'lsnodes -v' command.
If lsnodes shows that all members of the cluster are available, then you may have an rcp/rsh problem on Unix or shares have not been configured on Windows.
You can test rcp/rsh on Unix by issuing the following from each node:
[node1]/tmp> touch test.tst
[node1]/tmp> rcp test.tst node2:/tmp
[node2]/tmp> touch test.tst
[node2]/tmp> rcp test.tst node1:/tmp
On Windows, ensure that each node has administrative access to all these directories within the Windows environment by running the following at the command prompt:
NET USE \\host_name\C$
Clustercheck.exe also checks for this.
How do I stop the GSD?
If you are on 9.0 on Unix you would issue:
$ ps -ef
grep jre
$ kill -9
Stop the OracleGSDService on Windows.
Note: Make sure that this is the process in use by GSD
If you are on 9.2 you would issue:
$ gsdctl stop
How do I determine whether or not an OneOff patch is "rolling upgradeable"?
After you have downloaded a patch, you can go into the directory where you unpacked the patch:
> pwd
/ora/install/4933522
Then use the following OPatch command:
> opatch query is_rolling_patch
...
Query ...
Please enter the patch location:
/ora/install/4933522
---------- Query starts ------------------
Patch ID: 4933522
....
Rolling Patch: True.
---------- Query ends -------------------
Does Oracle RAC work with NTP (Network Time Protocol)?
YES! NTP and Oracle RAC are compatible, as a matter of fact, it is recommended to setup NTP in an Oracle RAC cluster, for Oracle 9i Database, Oracle Database 10g, and Oracle Database 11g Release 1.
With Oracle Database 11g Release 2, Oracle Clusterware includes the Cluster Time Synchronization Service (CTSS). On startup, Oracle Clusterware checks for a NTP configuration, if found, CTSS goes into Observer mode. This means it will monitor the clock synchronization and report in the Oracle Clusterware alert log if it finds a problem. If it does not find a NTP configuration, CTSS will be active. In active mode, CTSS synchronizes all the system clocks to the first node in the cluster.
From the Documentation:
Oracle® Database Oracle Clusterware and Oracle Real Application Clusters Installation Guide 10g Release 2 (10.2) for Linux B14203-05
page 2-21:
"Node Time Requirements
Before starting the installation, ensure that each member node of the cluster is set as closely as possible to the same date and time. Oracle strongly recommends using the Network Time Protocol feature of most operating systems for this purpose, with all nodes using the same reference Network Time Protocol server."
Each machine has a different clock frequency and as a result a slightly different time drift. NTP computes this time drift every about 15 minutes, and stores this information in a "drift" file, it then adjusts the system clock based on this known drift as well as compares it to a given time-server the sys-admins sets up. This is the recommended approach.
Keep the following points in mind:
Minor changes in time (in the seconds range) are harmless for Oracle RAC and the Oracle Clusterware. If you intend on making large time changes it is best to shutdown the instances and the entire Oracle Clusterware stack on that node to avoid a false eviction, especially if you are using the Oracle RAC 10g low-brownout patches, which allow really low misscount settings.
Backup/recovery aspect of large time changes are documented in Note: 77370.1, basically you can't use RECOVER DATABASE UNTIL TIME to reach the second recovery point, It is possible to overcome with RECOVER DATABASE UNTIL CANCEL or UNTIL CHANGE. If you are doing complete recovery (most of the times) then this is not an issue since the Oracle recovery code uses SCN (System Change Numbers) to advance in the redo/archive logs. The SCN numbers never go back in time (unless a reset-logs operation is performed), there is always an association of an SCN to a human readable timestamp (which may change forward or backwards), hence the issue with recovery until point in time vs. until SCN/Cancel.
If DBMS_SCHEDULER is in usage it will be affected by time changes, as it's using actual clock rather than SCN.
On platforms with OPROCD get fix for <> "OPROCD REBOOTS NODE WHEN TIME IS SET BACK BY XNTPD"
If NTP is not configured correctly (using -x flag), and diagwait not set to 13 Note: 559365.1 10.2/11.1 RAC systems can be rebooted due to OPROCD, during a leap second event, see Note: 759143.1.
Daylight saving time adjustments do not affect the system clock, only the displayed time, hence have no impact on the Oracle software.
Apart from these issues, the Oracle RDBMS server is immuned to time changes, i.e. will not affect transaction/read consistency operations.
The Oracle Clusterware requires the use of "-x" flag to the ntpd daemon to prevent the clock from going backwards (Enterprise Linux: see /etc/sysconfig/ntpd; Solaris: set "slewalways yes" in /etc/inet/ntp.conf)
If I am using Vendor Clusterware such as Veritas, IBM, Sun or HP, do I still need Oracle Clusterware to run Oracle RAC 10g or Oracle RAC 11g?
Yes. When certified, you can use Vendor clusterware however you must still install and use Oracle Clusterware for Oracle RAC. Best Practice is to leave Oracle Clusterware to manage Oracle RAC. For details see <
> and for Veritas SFRAC see Note: 397460.1.
How is Oracle Enterprise Manager integrated with the Oracle RAC 11g Release 2 stack?
Oracle Enterprise Manager (EM) is available in 2 versions: Oracle EM Grid Control and Oracle EM Database Control. Oracle EM Grid Control underlies adifferent release cycle than the Oracle Database, while the new version of Oracle EM Database Control is available with every new database release.
At the time of writing, Oracle EM Grid Control is available in version 10.2.0.5. This version does not support new features of the Oracle Database 11g Release 2. Oracle 11g Rel. 2 Database, however, can be managed with Oracle EM in the current version with some restrictions (no 11.2 feature support).
With Oracle Database and Grid Infrastructure 11g Release 2, Oracle EM Database Control is now able to manage the full Oracle RAC 11g Release 2 stack. This includes: Oracle RAC Databases, Oracle Clusterware, and Oracle Automatic Storage Management.
The new feature that needs to be noted here is the full management of Oracle Clusterware 11g Release 2 with Oracle EM Database Control 11g Release 2. For more information and details, see publicly available Technical White Paper: The New Oracle Enterprise Manager Database Control 11g Release 2 - Now Managing Oracle Clusterware
What storage option should I use for Oracle RAC on Linux? ASM / OCFS / Raw Devices / Block Devices / Ext3 ?
The recommended way to manage large amounts of storage in an Oracle RAC environment is ASM (Automatic Storage Management). If you really need/want a clustered filesystem, then Oracle offers OCFS (Oracle Clustered File System); for 2.4 kernel (RHEL3/SLES8) use OCFS Version 1 and for 2.6 kernel (RHEL4/SLES9) use OCFS2. All these options are free to use and completely supported, ASM is bundled in the RDBMS software, and OCFS as well as ASMLib are freely downloadable from Oracle's OSS (Open Source Software) website.
EXT3 is out of the question, since it's data structures are not cluster aware, that is, if you mount an ext3 filesystem from multiple nodes, it will quickly get corrupted.
Another option of course is NFS and iSCSI both are outside the scope of this FAQ but included for completeness.
If for any reason the above options (ASM/OCFS) are not good enough and you insist on using 'raw devices' or 'block devices' here are the details on the two (This information is still very useful to know in the context of ASM and OCFS).
On Unix/Linux there are two types of devices:
block devices (/dev/sde9) are **BUFFERED** devices!! unless you explicitly open them in O_DIRECT you will get buffered (linux buffer cache) IO.
character devices (/dev/raw/raw9) are *UN-BUFFERRED** devices!! no matter how you open them, you always get unbufferred IO, hence no need to specify O_DIRECT on the file open call.
Above is not a typo, block devices on Unix do buffered IO by default (cached in linux buffer cache), this means that RAC can not operate on it (unless opened with O_DIRECT), since the IO's will not be immediately visible to other nodes.
You may check if a device is block or character device by the first letter printed with the "ls -l" command:
crw-rw---- 1 root disk 162, 1 Jan 23 19:53 /dev/raw/raw1
brw-rw---- 1 root disk 8, 112 Jan 23 14:51 /dev/sdh
Above, "c" stands for character device, and "b" for block devices.
Starting with Oracle 10.1 an RDBMS fix added the O_DIRECT flag to the open call (O_DIRECT flag tells the Linux kernel to bypass the Linux buffer cache and write directly to disk), in the case of a block device, that ment that a create datafile on '/dev/sde9' would succeed (need to set filesystemio_options=directio in init.ora).. This enhancement was well received, and shortly after bug 4309443 was fixed (by adding the O_DIRECT flag on the OCR file open call) meaning that starting with 10.2 (there are several 10.1 backports available) the Oracle OCR file could also access block devices directly. For the voting disk to be opened with O_DIRECT you need fix for bug 4466428 (5021707 is a duplicate). This means that both voting disks and OCR files could live on block devices. However, due to OUI bug 5005148, there is still a need to configure raw devices for the voting or OCR files during installation of RAC, not such a big deal, since it's just 5 files in most cases. It is not possible to ask for a backport of this bug since it means a full re-release of 10g, one alternative if raw devices are not a good option is to use 11g Clusterware (with 10g RAC database).
By using block devices you no longer have to live with the limitations of 255 raw devices per node. You can access as many block devices as the system can support. Also block devices carry persistent permissions across reboots, while with raw devices one would have to customize that after installation otherwise the Clusterware stack or database would fail to startup due to permission issues.
ASM or ASMlib can be given the raw devices (/dev/raw/raw2) as was done in the initial deployment of 10g Release 1, or the more recommended way: ASM/ASMLib should be given the block devices directly (eg. /dev/sde9).
Since RAW devices are being phased out of Linux in the long term, it is recommended everyone should switch to using the block devices (meaning, pass these block devices to ASM or OCFS/2 or Oracle Clusterware)
Note: With Oracle Database 11g Release 2, Oracle Clusterware files (OCR and Voting Disk can be store in ASM and this is the Best Practice). The Oracle Universal Installer and the configuration assistants (IE DBCA, NETCA) will not support raw/block devices. All command line interfaces will support raw/block for this release. Therefore if you are using raw/block today, you can continue to use it and upgrading to 11g Release 2 will not change the location of any files. However due to the desupport in the next release, you are recommended to plan a migration to a supported storage option. All files supported natively in ASM, will not be supported in production with the ASM Cluster File System (ACFS)
What are the implications of using srvctl disable for an instance in my Oracle RAC cluster? I want to have it available to start if I need it but at this time to not want to run this extra instance for this database.
During node reboot, any disabled resources will not be started by the Clusterware, therefore this instance will not be restarted. It is recommended that you leave the vip, ons,gsd enabled in that node. For example, VIP address for this node is present in address list of database services, so a client connecting to these services will still reach some other database instance providing that service via listener redirection. Just be aware that by disabling an Instance on a node, all that means is that the instance itself is not starting. However, if the database was originally created with 3 instances, that means there are 3 threads of redo. So, while the instance itself is disabled, the redo thread is still enabled, and will occasionally cause log switches. The archived logs for this 'disabled' instance will still be needed in any potential database recovery scenario. So, if you are going to disable the instance through srvctl, you may also want to consider disabling the redo thread for that instance.
srvctl disable instance -d orcl -i orcl2
SQL> alter database disable public thread 2;
Do the reverse to enable the instance.
SQL> alter database enable public thread 2;
srvctl enable instance -d orcl -i orcl2
If using plsql native code, the plsql_native_library_dir needs to be defined. In an Oracle RAC environement, must the directory be in the shared storage?
In Oracle RAC configuration, this parameter must be set in each instance. The instances are not required to have a shared file system. On each instance the plsql_native_library_dir can be set to point to an instance local directory. Alternately, if the Oracle RAC configuration supports a shared (cluster) file system, you can use a common directory (on the shared file system) for all instances. You can also check out the PL/SQL Native Compilation FAQ on OTN: www.oracle.com/technology/tech/pl_sql/htdocs/ncomp_faq.html With Oracle RAC 11g Release 2, use ACFS (ASM Cluster file system)
What is the purpose of the gsd service in Oracle 9i RAC?
GSD is only needed for configuration/management of cluster database. Once database has been configured and up, it can be safely stopped provided you don't run any 'srvctl or dbca or dbua' tools. In Oracle 9i RAC, the GSD doesn't write anywhere unless tracing was turned on, in which case traces go to stdout.
Once the database has been configured and started and you don't use 'srvctl or EM' to manage or 'dbca to extend/remove' or 'dbua to upgrade' this database, GSD can be stopped.
Note: With Oracle RAC 11g Release 2, the gsd resource is disabled by default. You will only need to enable the resource if you are running Oracle 9i RAC in the same cluster.
How do I identify which node was used to install the cluster software and/or database software?
You can find out which node by running olsnodes command. The node which is returned first is the node from which the software was installed and patches should be installed.
Note: When applying patches in a rolling fashion, you are recommended to run the rolling scripts from the last node added to the cluster first and follow the list in reverse order.
Are the Oracle Clusterware bundle patches cumulative, do they conflict with one another?
Fix-wise, the Oracle Clusterware bundles are cumulative, that is, CRS bundle #3 fixes all the issues that bundle #2 did, and some additional ones, see Note:405820.1 for complete list of bugs fixed in each bundle.
However, OPatch does not allow to apply ANY patch if there are any overlapping libs or binaries between an already existing patch and the to-be-installed patch.
If two patches touch a particular file, e.g: kcb.o, then the existing patch must be manually removed before the new applied.
So, bundle patches are cumulative, however they do conflict with one another due to the way OPatch allows patch application, hence previous bundle must be manually removed before a new one is applied.
To check if any two patches conflict invoke OPatch as per Note:458485.1 or using:
$ OPatch/opatch prereq CheckConflictAmongPatches -phbasefile patchlist
where patchlist is a text file containing all the patch numbers to be checked, separated by a newline.
I have added a second network to my cluster, can I load balance my users across this network?
Server side load balancing will only work on a single network which is configured as the public network with the Oracle VIPS. If you add a second network, with a second listener, do not add this new listener to the local_listener and remote_listener parameter. You can use client-side load balancing and failover for users connecting to this network however you will be unable to use server-side load balancing or receive FAN events for this network.
Oracle RAC 11g Release 2 adds the support for multiple public networks. Connections will be load balanced across the instances. Each network will have its own service. To enable load balancing use the LISTENER_NETWORKS parameter instead of LOCAL_LISTENER and REMOTE_LISTENER.
Srvctl cannot start instance, I get the following error PRKP-1001 CRS-0215, however sqlplus can start it on both nodes? What is the problem?
This could be many things but a popular issue is when you have a separate ASM Home and the listener is running out of this home (it was the first home installed). Srvctl needs a TNS_ADMIN alias to the network/admin directory in this home instead of using the default ORACLE_HOME/network/admin for the database you are trying to start. For srvctl to work you must
srvctl setenv nodeapps -n node -T TNS_ADMIN=full path
on each node in the cluster.
You cannot rely on a TNS_ADMIN environment variable.
See Note 420977.1
Another cause is non-existent spfile, see Note 732683.1
When I look at ALL_SERVICES view in my database I see services I did not create, what are they for?
You will always see a default database service that is the same name as your database. This service is available on all instances in the cluster. You will also see two services used by the database SYS$BACKGROUND (for background processes) and SYS$USERS (users who connect via BEQ or without using a service_name). You may also see services that end with XDB which are created for the XML DB feature and you will not be able to manage these services.
I have 2 clusters named "crs" (the default), how do I get Grid Control to recognize them as targets?
There are 2 options:
a) if the grid control agent install (which is a separate install) has already been done and has picked up the name of the cluster as it was configured as CRS, one can go to the EM console as is, and for the second, manually delete and rediscover the target. When you rediscover the target, give whatever display name you like
b) Prior to performing the Grid control agent install, just set CLUSTER_NAME environment variable and run the install. This variable need to be set only for that install session. No need to set it every time agent starts.
I found in 10.2 that the EM "Convert to Cluster Database" wizard would always fall over on the last step where it runs emca and needs to log into the new cluster database as dbsnmp to create the cluster database targets etc. I changed the password for the dbsnmp account to be dbsnmp (same as username) and it worked OK. Is this a known issue?
The conversion to cluster happens successfully but the EM monitoring credentials for the converted database are not properly set due to this bug. This is resolved in next patchset. In the interim, user can set the monitoring password from the "monitoring configuration" screen for the RAC DB from GC console and proceed.
This issue has been fixed in 10.2.0.3 database and to get the complete functionality you will need 10.2.0.2 Grid Control patch also, as the fix is spread between the two pieces of software. For now you can proceed with setting password for dbsnmp user same as that of sys user.
What is the Cluster Verification Utiltiy (cluvfy)?
The Cluster Verification Utility (CVU) is a validation tool that you can use to check all the important components that need to be verified at different stages of deployment in a RAC environment. The wide domain of deployment of CVU ranges from initial hardware setup through fully operational cluster for RAC deployment and covers all the intermediate stages of installation and configuration of various components. Cluvfy does not take any corrective action following the failure of a verification task, does not enter into areas of performance tuning or monitoring, does not perform any cluster or RAC operation, and does not attempt to verify the internals of cluster database or cluster elements.
What versions of the database can I use the cluster verification utility (cluvfy) with?
The cluster verification utility is release with Oracle Database 10g Release 2 but can also be used with Oracle Database 10g Release 1.
How many nodes can be had in an HP-UX/Solaris/AIX/Windows/Linux cluster?
The number of nodes supported is not limited by Oracle, but more generally by the clustering software/hardware in question.
When using solely Oracle Clusterware: 63 nodes (Oracle 9i or Oracle RAC 10g Release 1) With 10g Release 2, the maximum nodes is 100
When using a third party clusterware:
Sun: 8
HP UX: 16
HP Tru64: 8
IBM AIX:
* 8 nodes for Physical Shared (CLVM) SSA disk
* 16 nodes for Physical Shared (CLVM) non-SSA disk
* 128 nodes for Virtual Shared Disk (VSD)
* 128 nodes for GPFS
* Subject to storage subsystem limitations
Veritas: 8-16 nodes (check w/ Veritas)
For 3rd party vendor clusterware, please check with the vendor.
Is crossover cable supported as an interconnect with RAC on any platform ?
NO. CROSS OVER CABLES ARE NOT SUPPORTED. The requirement is to use a switch:
Detailed Reasons:
1) cross-cabling limits the expansion of RAC to two nodes
2) cross-cabling is unstable:
a) Some NIC cards do not work properly with it. They are not able to negotiate the DTE/DCE clocking, and will thus not function. These NICS were made cheaper by assuming that the switch was going to have the clock. Unfortunately there is no way to know which NICs do not have that clock.
b) Media sense behaviour on various OS's (most notably Windows) will bring a NIC down when a cable is disconnected. Either of these issues can lead to cluster instability and lead to ORA-29740 errors (node evictions).
Due to the benefits and stability provided by a switch, and their afforability ($200 for a simple 16 port GigE switch), and the expense and time related to dealing with issues when one does not exist, this is the only supported configuration.
From a purely technology point of view Oracle does not care if the customer uses cross over cable or router or switches to deliver a message. However, we know from experience that a lot of adapters misbehave when used in a crossover configuration and cause a lot of problems for RAC. Hence we have stated on certify that we do not support crossover cables to avoid false bugs and finger pointing amongst the various parties: Oracle, Hardware vendors, Os vendors etc...
Is it possible to run Oracle RAC on logical partitions (i.e. LPARs) or virtual separate servers.
Yes, it is possible. Check Certify to understand the current details for the different hardware solutions.
On high end servers can be partitioned into domains (partitions) of smaller sizes, each domain with its own CPU(s) and operating system. Each domain is effectively a virtual server. Oracle RAC can be run on cluster comprises of domains. The benefits of using this is similar to a regular cluster, any domain failure will have little effect on other domains. Besides, the management of the cluster may be easier since there is only one physical server. Note however, since one E10K is still just one server. There are single points of failures. Any failures, such as back plane failure, that crumble the entire server will shutdown the virtual cluster. That is the tradeoff users have to make in how best to build a cluster database.
How do I check Oracle RAC certification?
See the following Metalink note: Note 184875.1 Please note that certifications for Oracle Real Application Clusters are performed against the Operating System and Clusterware versions. The corresponding system hardware is offered by System vendors and specialized Technology vendors. Some system vendors offer pre-installed, pre-configured Oracle RAC clusters. These are included below under the corresponding OS platform selection within the certification matrix.
What is Oracle's position with respect to supporting RAC on Polyserve CFS?
Please check the certification matrix available through Metalink for your specific release.
Can the Oracle Database Configuration Assistant (DBCA) be used to create a database with Veritas DBE / AC 3.5?
DBCA can be used to create databases on raw devices in 9i RAC Release 1 and 9i Release 2. Standard database creation scripts using SQL commands will work with file system and raw.
DBCA cannot be used to create databases on file systems on Oracle 9i Release 1. The user can choose to set up a database on raw devices, and have DBCA output a script. The script can then be modified to use cluster file systems instead.
With Oracle 9i RAC Release 2 (Oracle 9.2), DBCA can be used to create databases on a cluster filesystem. If the ORACLE_HOME is stored on the cluster filesystem, the tool will work directly. If ORACLE_HOME is on local drives on each system, and the customer wishes to place database files onto a cluster file system, they must invoke DBCA as follows: dbca -datafileDestination /oradata where /oradata is on the CFS filesystem. See 9iR2 README and bug 2300874 for more info.
Is Oracle Database on VMware support? Is Oracle RAC on VMware supported?
Oracle Database support on VMware is outlined in Metalink Note 249212.1. Effectively, for most customers, this means they are not willing to run production Oracle databases on VMware. Regarding Oracle RAC - the explicit mention not to run RAC on vmware was removed in 11.2.0.2 (Novemeber 2010)
Is Veritas Storage Foundation supported with Oracle RAC?
Veritas certifies Veritas Storage Foundation for Oracle RAC with each release. Check Ceritify and Veritas Support Matrix for the latest details.
After installing patchset 9013 and patch_2313680 on Linux, the startup was very slow
Please carefully read the following new information about configuring Oracle Cluster Management on Linux, provided as part of the patch README:
Three parameters affect the startup time:
soft_margin (defined at watchdog module load)
-m (watchdogd startup option)
WatchdogMarginWait (defined in nmcfg.ora).
WatchdogMarginWait is calculated using the formula:
WatchdogMarginWait = soft_margin(msec) + -m + 5000(msec).
[5000(msec) is hardcoded]
Note that the soft_margin is measured in seconds, -m and WatchMarginWait are measured in milliseconds.
Based on benchmarking, it is recommended to set soft_margin between 10 and 20 seconds. Use the same value for -m (converted to milliseconds) as used for soft_margin. Here is an example:
soft_margin=10 -m=10000 WatchdogMarginWait = 10000+10000+5000=25000
If CPU utilization in your system is high and you experience unexpected node reboots, check the wdd.log file. If there are any 'ping came too late' messages, increase the value of the above parameters.
Is there a cluster file system (CFS) Available for Linux?
Yes, ACFS (ASM Cluster File System with Oracle Database 11g Release 2) and OCFS (Oracle Cluster Filesystem) are available for Linux. The following Metalink note has information for obtaining the latest version of OCFS:
Note 238278.1 - How to find the current OCFS version for Linux
Is the hangcheck timer still needed with Oracle RAC 10g and 11gR1?
YES! hangcheck-timer is required for 10g and 11gR1 (11.1.*). It is no longer needed in Oracle Clusterware 11gR2.
The hangcheck-timer module monitors the Linux kernel for extended operating system hangs that could affect the reliability of the RAC node ( I/O fencing) and cause database corruption. To verify the hangcheck-timer module is running on every node:
as root user:
/sbin/lsmod
grep hangcheck
If the hangcheck-timer module is not listed enter the following command as the root user:
9i: /sbin/insmod hangcheck-timer hangcheck_tick=30 hangcheck_margin=180 hangcheck_reboot=1
10g & 11gR1: /sbin/insmod hangcheck-timer hangcheck_tick=1 hangcheck_margin=10 hangcheck_reboot=1
To ensure the module is loaded every time the system reboots, verify that the local system startup file (/etc/rc.d/rc.local) contains the command above.
For additional information please review the Oracle RAC Install and Configuration Guide (5-41) and note:726833.1.
Oracle Clusterware fails to start after a reboot due to permissions on raw devices reverting to default values. How do I fix this?
After a successful installation of Oracle Clusterware a simple reboot and Oracle Clusterware fails to start. This is because the permissions on the raw devices for the OCR and voting disks e.g. /dev/raw/raw{x} revert to their default values (root:disk) and are inaccessible to Oracle. This change of behavor started with the 2.6 kernel; in RHEL4, OEL4, RHEL5, OEL5, SLES9 and SLES10. In RHEL3 the raw devices maintained their permissions across reboots so this symptom was not seen.
The way to fix this is on RHEL4, OEL4 and SLES9 is to create /etc/udev/permission.d/40-udev.permissions (you must choose a number that's lower than 50). You can do this by copying /etc/udev/permission.d/50-udev.permissions, and removing the lines that are not needed (50-udev.permissions gets replaced with upgrades so you do not want to edit it directly, also a typo in the 50-udev.permissions can render the system non-usable). Example permissions file:
# raw devices
raw/raw[1-2]:root:oinstall:0640
raw/raw[3-5]:oracle:oinstall:0660
Note that this applied to all raw device files, here just the voting and OCR devices were specified.
On RHEL5, OEL5 and SLES10 a different file is used /etc/udev/rules.d/99-raw.rules, notice that now the number must be (any number) higher than 50. Also the syntax of the rules is different than the permissions file, here's an example:
KERNEL=="raw[1-2]*", GROUP="oinstall", MODE="640"
KERNEL=="raw[3-5]*", OWNER="oracle", GROUP="oinstall", MODE="660"
This is explained in detail in Note: 414897.1 .
How do I configure raw devices in order to install Oracle Clusterware 10g on RHEL5 or OEL5?
The raw devices OS support scripts like /etc/sysconfig/rawdevices are not shipped on RHEL5 or OEL5, this is because raw devices are being deprecated on Linux. This means that in order to install Oracle Clusterware 10g you'd have to manually bind the raw devices to the block devices for the OCR and voting disks so that the 10g installer will proceed without error.
Refer to Note 465001.1 for exact details on how to do the above.
Oracle Clusterware 11g doesn't require this configuration since the installer can handle block devices directly.
Can different releases of Oracle RAC be installed and run on the same physical Linux cluster?
Yes - However Oracle Clusterware (CRS) will not support a Oracle 9i RAC database so you will have to leave the current configuration in place. You can install Oracle Clusterware and Oracle RAC 10g or 11g into the same cluster. On Windows and Linux, you must run the 9i Cluster Manager for the 9i Database and the Oracle Clusterware for the 10g Database. When you install Oracle Clusterware, your 9i srvconfig file will be converted to the OCR. Oracle 9i RAC, Oracle RAC 10g, and Oracle RAC 11g will use the OCR. Do not restart the 9i gsd after you have installed Oracle Clusterware. Remember to check certify for details of what vendor clusterware can be run with Oracle Clusterware. Oracle Clusterware must be the highest level (down to the patchset). IE Oracle Clusterware 11g Release 2 will support Oracle RAC 10g and Oracle RAC 11g databases. Oracle Clusterware 10g can only support Oracle RAC 10g databases.
Is 3rd Party Clusterware supported on Linux such as Veritas or Redhat?
No, Oracle RAC 10g and Oracle RAC 11g do not support 3rd Party clusterware on Linux. This means that if a cluster file system requires a 3rd party clusterware, the cluster file system is not supported.
A customer installed 10g Release 2 on Linux RH4 Update 2, 2.6.9-22.ELsmp #1 SMP x86_64 GNU/Linux, and got the error Error in invoking target 'all_no_orcl'. Customer ignored the error and the install succeeded without any other errors and oracle apparently worked fine. What should they do?
Because of compatibility with their storage array (EMC DMX with Powerpath 4.5) they must use update 2. Oracle install guide states that RH4 64 bits update 1 "or higher" should be used for 10g R2.
The binutils patch binutils-.15.92.0.2-13.0.0.0.2.x86_64.rpm is needed to relink without error. Red Hat is aware of the bug. Customers should use the latest update (or at least update 3 to fix).
Is OCFS2 certified with Oracle RAC 10g?
Yes. See Certify to find out which platforms are currently certified.
How do I configure my RAC Cluster to use the RDS Infiniband?
The configuration takes place below Oracle. You need to talk to your Infiniband vendor. Check certify for what is currently available as this will change as vendors adopt the technology. The database must be at least 10.2.0.3. If you want to switch a database running with IP over IB, you will need to relink Oracle.
$ cd $ORACLE_HOME/rdbms/lib $ make -f ins_rdbms.mk ipc_rds ioracle
You can check your interconnect through the alert log at startup. Check for the string “cluster interconnect IPC version:Oracle RDS/IP (generic)” in the alert.log file.
See Note: 751343.1 for more details.
Customer did not load the hangcheck-timer before installing RAC, Can the customer just load the hangcheck-timer ?
YES. hangcheck timer is a kernel module that is shipped with the Linux kernel, all you have to do is load it as follows:
9i: /sbin/insmod hangcheck-timer hangcheck_tick=30 hangcheck_margin=180 hangcheck_reboot=1
10g & 11g: /sbin/insmod hangcheck-timer hangcheck_tick=1 hangcheck_margin=10 hangcheck_reboot=1
No need to reboot the nodes.
For more details see note:726833.1
How to reorder or rename logical network interface (NIC) names in Linux
Although this is rarely needed, since most hardware will detect the cards in the correct order on all nodes, if you still need to change/control the ordering, see external website, here is more help on writing UDEV rules.
Are Red Hat GFS and GULM certified for DLM?
Both are part of Red Hat RHEL 5. For Oracle Database 10g Release 2 on Linux x86 and Linux x86-64, it is certified on OEL5 and RHEL5 as per certify. GFS is not certified yet , certification in progress by RedHat. OCFS2 is certified and it's the preferred choice for Oracle. ASM is recommended storage for the database. Since GFS is part of the RHEL5 distribution and Oracle fully supports RHEL under the Unbreakable Linux Progam, Oracle will support GFS as part of RHEL5 for customers buying the Unbreakable Linux Support. This only applies to RHEL5 and not to RHEL4 where GFS is distributed with an additional fee
My customer is about to install 10202 clusterwere on new Linux machinges. He is getting "No ORACM running" error when run rootpre.sh and exited? Should he worry about this message?
It is an informational message. Generally for such scripts, you can issue echo “$?” to ensure that it returns a zero value. The message is basically saying, it did not find an oracm. If Customer were installing 10g on an existing 9i cluster (which will have oracm) then this message would have been serious. But since customer is installing this on a fresh new box, They can continue the install.
How to configure bonding on Suse SLES8.
Please see note:291958.1
How to configure bonding on Suse SLES9.
Please see note:291962.1
In Solaris 10, do we need Sun Cluster to provide redundancy for the interconnect and multiple switches?
Link Aggregation (GLDv3) is bundled in the OS as of Solaris 10. IPMP is available for Solaris 10 and Solaris 9. Neither require Sun Cluster to be installed. For the interconnect and switch redundancy, as a best practice, avoid VLAN trunking across the switches. We can configure stand-alone redundant switches that do not require the VLAN to be trunked between them, nor the need for an inter-switch link (ISL). If the interconnect VLAN is trunked with other VLANS between the redundant switches, insure that the interconnect VLAN is pruned from the trunk to avoid unnecessary traffic propagation through the corportate network. For ease of configuration (e.g. fewer IP address requirements), use IPMP with link mode failure detection in primary/standby configuration. This will give you a single failover IP which you will define in cluster_interconnects init.ora parameter. Remove any interfaces for the interconnect from the OCR using `oifcfg delif`. AND TEST THIS RIGOROUSLY. For now, as Link Aggregation (GLDv3) cannot span multiple switches from a single host, you will need to configure the switch redundancy and the host NICs with IPMP. When configuring IPMP for the interconnect with multiple switches available, configure IPMP as active/standby and *not* active/active. This is to avoid potential latencies in switch failure detection/failover which may impact the availability of the rdbms. Note, IPMP spreads/load balances outbound packets on the bonded interfaces, but inbound packets are received on a single interface. In an active/active configuration this makes send/receive problems difficult to diagnose. Both Link Aggregation (GLDv3) and IPMP are core OS packages SUNWcsu, SUNWcsr respectively and do not require Sun Clusterware.
Can I configure IPMP in Actie/Active to increase bandwidth of my interconnect?
For IPMP For active/active configurations please follow the sun doc instructions http://docs.sun.com/app/docs/doc/816-4554/6maoq027i?a=view IPMP active/active is known to load balance on transmit but serialize on a single interface for receive. So you are likely not to get the throughput you might have expected. Unless you experience explicit bandwidth limitations that require active/active, it is a recommended best practice to configure for maximum availability, as described in webiv note 283107.1.
Please note too that debugging active/active interfaces at the network layer is cumbersome and time consuming. In an active/active configuration and the switch side link fails, you are likely to lose both interconnect connections, whereas active/standby, you would failover.
Does Sun Solaris have a multipathing solution ?
Sun Solaris includes an inherent Multipathing tool: MPXIO - this is part of Solaris. You need to have the SanFoundation Kit installed (newest version). Please, be aware that the machines are installed following the EIS-standard. This is a quality assurance standard introduced by Sun that mainly takes care that you always have the newest patches.
MPXIO is free of charge and comes with Solaris 8,9,10. BTW, if you have a Sun LVM, it would use this feature indirectly. Therefore, Sun confirmed that MPXIO will work with RAWs.
Can I configure HP's Autoport aggregation for NIC Bonding after the install? (i.e. not present beforehand)
You are able to add NIC bonding after the installation although this is more complicated than the other way round.
There are several notes on webiv regarding this.
Note 276434.1 Modifying the VIP of a Cluster Node
Regarding the private interconnect, please use oifcfg delif / setif to modify this.
Configure Redundant Network Cards / Switches for Oracle Database 10g Release 1 Real Application Cluster on Linux
Is HMP supported with Oracle RAC 10g or Oracle RAC 11g on all HP platforms ?
HP has desupported HMP with Oracle RAC 10g. See http://docs.hp.com/en/B6257-90056/ch01s01.html?jumpid=reg_R1002_USEN
Does the Oracle Cluster File System (OCFS) support network access through NFS or Windows Network Shares?
No, in the current release the Oracle Cluster File System (OCFS) is not supported for use by network access approaches like NFS or Windows Network Shares.
Why should I use RAC One Node instead of Oracle Fail Safe on Windows?
Oracle RAC One Node provides better high availability than Oracle Fail Safe. RAC One Node's ability to online relocate a database offers protection from both unplanned failures and maintenance outages. Fail Safe only protects from failures and cannot online relocate a database. RAC One Node supports online maintenance operations such as online database patches, online OS patches and upgrades, online database relocation for load balancing, online server migrations, and online upgrade to full RAC. In an environment where it is difficult to get windows of downtime for maintenance, this is a big advantage. Also, where Fail Safe is only available on Windows, RAC One Node is available on all platforms. A customer with a mixed platform environment would benefit from having a standard HA solution across all their platforms.
When running Oracle RAC on Windows 2003, what is the recommended OS level?
It is strongly recommended to be at SP2 on Windows 2003. For details see the following Notes:
Note: 464683.1 - Unexplained Database Slowdown Seen on Windows 2003 Service Pack 1
Note: 454607.1 - New Partitions in Windows 2003 RAC Environments Not Visible on Remote Nodes
For details on Windows Bundle patches see:
Note: 342443.1 - 10.2.0.x Oracle Database and Networking Patches for Microsoft Platforms
Can I run my Oracle 9i RAC and Oracle RAC 10g on the same Windows cluster?
Yes but the Oracle 9i RAC database must have the 9i Cluster Manager and you must run Oracle Clusterware for the Oracle Database 10g. 9i Cluster Manager can coexsist with Oracle Clusterware 10g.
Be sure to use the same 'cluster name' in the appropriate OUI field for both 9i and 10g when you install both together in the same cluster.
The OracleCMService9i service will remain intact during the Oracle Clusterware 10g install, as a Oracle 9i RAC database would require that the 9i OracleCMService9i, it should be left running. The information for the 9i database will get migrated to the OCR during the Oracle Clusterware installation. Then, for future database management, you would use the 9i srvctl to manage the 9i database, and the 10g srvctl to manage any new 10g databases. Both srvctl commands will use the OCR. The same applies for Oracle RAC 11g
When using MS VSS on Windows with Oracle RAC, do I need to run the VSS on each node where I have an Oracle RAC instance?
There is no need to run Oracle VSS writer instance on each Oracle RAC node (even though it is installed and enabled by default on all nodes). And the documentation in Windows Platform Doc for Oracle VSS writer is applicable to Oracle RAC also.
The ability of clustered file system to create a Windows Shadow copy is a MUST to backup Oracle RAC database using Oracle VSS writer. The only other requirement is that, all the archived logs generated by database must be accessible on node where backup is initiated using Oracle VSS writer.
VSS coordinates storage snapshot of db files - the VSS writer places the db in hot backup mode so that the VSS provider can initiate the snapshot. So, RMAN is not backing up anything in this case. When a VSS restore of a db is issued, the writer automatically invokes RMAN to perform needed recovery actions after the snapshot is restored by the provider - that is the real value add of the writer.
What do I do when I get an ORA-01031 error logging into the ASM instance?
This sounds like the ORA_DBA group on Node2 is empty, or else does not have the correct username in it. Double-check what user account you are using to logon to Node2 as ( a 'set' command will show you the USERNAME and USERDOMAIN values) and then make sure that this account is part of ORA_DBA.
The other issue to check is that SQLNET.AUTHENTICATION_SERVICES=(NTS) is set in the SQLNET.ORA
The OracleCRService does not start with my windows Oracle RAC implementation, what do I do?
If OracleCRService doesn't start that's quite a different issue than say OracleCSService not starting - because due to dependencies, this is the last of the three Oracle Clusterware services that we expect to start. This could be caused by a few different things. It could be caused by a change from to auto-negotiate instead of 100/full on the interconnect. Once set back to 100/full on all NICs as well as the network switch associated with the interconnect the problem is resolved. This could also be: - inability to access the shared disk housing your OCR - permissions issue OR - Bug:4537790 which introduced OPMD to begin with - which for reference sake was logged against 9.2.0.8 ... and is still relevant today in 10.2.0.3 times. For OPMD, see Metalink Note 358156.1
How do I verify that Host Bus Adapter Node Local Caching has been disabled for the disks I will be using in my RAC cluster?
Disabling write caching is a standard practice while using the volume managers/file systems are shared. Go to My computer -> Manage->Storage->Disk Management->Disk-Properties->Policies-> and uncheck the "Enable Write Caching on Disk". This will disable the write caching.
3rd party HBA's may have their own management tools to modify these settings. Just remember that centralized, shared cache is generally OK. It's the node local cache that you need to turn off. How exactly you do this will vary from HBA vendor to HBA vendor.
My customer has a failsafe cluster installed, what are the benefits of moving their system to RAC?
Fail Safe development is continuing. Most work on the product will be around accomodating changes in the supported resources (new releases of RDBMS, AS, etc.) and the underlying Microsoft Cluster Services and Windows operating system.
A failsafe protected instance is an Active/Passive instance so, as such, does not benefit that much at all from adding more nodes to a cluster. Microsoft have a limit of nodes in a MSCS cluster. (typically 8 nodes - but it does vary). RAC is active active so you get dual benefits of increased scalability and availability every time you add a node to a cluster. We have a limit of 100 nodes in a RAC cluster (we don't use MSCS). Your customer should really consider more than 2 nodes. (because of aggregate computer power on node failure). If the choice is 2 of 4 CPU nodes or 4 of 2CPU node then I would go for 2 CPU nodes. Customers are using both Windows Itanium RAC and Windows X64 RAC. Windows X64 seems more popular.
Keep in mind, though, that for Fail Safe, if the server is 64-Bit, regardless of flavor, Fail Safe Manager must be installed on a 32-Bit client, which will complicate things just a bit. There is no such restriction for RAC, as all management for RAC can be done via Grid Control or Database Control.
For EE RAC you can implement an 'extended cluster' where there is a distance between the nodes in the cluster (usually less than 20 KM).
My customer wants to understand what type of disk caching they can use with their Windows RAC Cluster, the install guide tells them to disable disk caching?
If the write cache identified is local to the node then that is bad for RAC. If the cache is visible to all nodes as a 'single cache', typically in the storage array, and is also 'battery backed' then that is OK.
Do I need HACMP/GPFS to store my OCR/Voting file on a shared device.
The prerequisites doc for AIX clearly says:
"If you are not using HACMP, you must use a GPFS file system to store the Oracle CRS files" ==> this is a documentation bug and this will be fixed with 10.1.0.3
Note also that on AIX it is important to use the reserve_lock=no/reserve_policy =no_reserve per shared, concurrent device in order to allow AIX to access the devices from more than one node simultaneously. Check the current setting using: "/usr/sbin/lsattr -El hdiskn
grep reserve".
Depending on the type of storage used, the command should return "no_reserve" or a similar value for all disks meant to be used for Oracle RAC. If requiredd, use the /dev/rhdisk devices (character special) for the crs and voting disk and change the attribute with the following command
chdev -l hdiskn -a reserve_lock=no
(for ESS, EMC, HDS, CLARiiON, and MPIO-capable devices you have to do an chdev -l hdiskn -a reserve_policy=no_reserve)
Is VIO supported with RAC on IBM AIX?
VIO is supported on IBM AIX. Please check ** Certify Unix RAC Technology Matrix ** for the details.
Is HACMP needed for RAC on AIX 5.2 using GPFS file system?
The newest version of GPFS can be used without HACMP, if it is available for AIX 5.2 then you do not need HACMP.
Can I run Oracle RAC 10g on my IBM Mainframe Sysplex environment (z/OS)?
YES! There is no separate documentation for RAC on z/OS. What you would call "clusterware" is built in to the OS and the native file systems are global. IBM z/OS documentation explains how to set up a Sysplex Cluster; once the customer has done that it is trivial to set up a RAC database. The few steps involved are covered in in Chapter 14 of the Oracle for z/OS System Admin Guide, which you can read here. There is also an Install Guide for Oracle on z/OS ( here) but I don't think there are any RAC-specific steps in the installation. By the way, RAC on z/OS does not use Oracle's clusterware (CSS/CRS/OCR).
Can I use Oracle Clusterware for failover of the SAP Enqueue and VIP services when running SAP in a RAC environment?
Oracle has created sapctl to do this and it is available for certain platforms. SAPCTL will be available for download on SAP Services Marketplace on AIX and Linux. For Solaris, it will not be available in 2007, use Veritas or Sun Cluster.
Are Oracle Applications certified with RAC?
For Siebel, PeopleSoft see http://realworld.us.oracle.com/isv/siebel.htm Oracle 9i RAC (9.2) and Oracle RAC 10g (10.1) are certified with Oracle Applications EBusiness Suute. See Note: 285267.1 for details.
What are the cdmp directories in the background_dump_dest used for?
These directories are produced by the diagnosibility daemon process (DIAG). DIAG is a database process which as one of its tasks, performs cache dumping. The DIAG process dumps out tracing to file when it discovers the death of an essential process (foreground or background) in the local instance. A dump directory named something like cdmp_ is created in the bdump or background_dump_dest directory, and all the trace dump files DIAG creates are placed in this directory.
How do I gather all relevant Oracle and OS log/trace files in an Oracle RAC cluster to provide to Support?
Use RAC-DDT (RAC Diagnostic Data Tool), User Guide is in Note: 301138.1. Quote from the User Guide:
RACDDT is a data collection tool designed and configured specifically for gathering diagnostic data related to Oracle's Real Application Cluster (RAC) technology. RACDDT is a set of scripts and configuration files that is run on one or more nodes of an Oracle RAC cluster. The main script is written in Perl, while a number of proxy scripts are written using Korn shell. RACDDT will run on all supported Unix and Linux platforms, but is not supported on any Windows platforms.
Newer versions of RDA (Remote Diagnostic Agent) have the RAC-DDT functionality, so going forward RDA is the tool of choice. The RDA User Guide is inNote: 314422.1
What is the optimal migration path to be used while migrating the E-Business suite to Oracle RAC?
Following is the recommended and most optimal path to migrate you E-Business suite to an Oracle RAC environment:
1. Migrate the existing application to new hardware. (If applicable).
2. Use Clustered File System (ASM recommended) for all data base files or migrate all database files to raw devices. (Use dd for Unix or ocopy for NT)
3. Install/upgrade to the latest available e-Business suite.
4. Ensure the database version is supported with Oracle RAC
5. In step 4, install Oracle RAC option and use Installer to perform install for all the nodes.
6. Clone Oracle Application code tree.
Reference Documents:
Oracle E-Business Suite Release 11i with 9i RAC: Installation and Configuration : <>
E-Business Suite 11i on RAC : Configuring Database Load balancing & Failover: <>
Oracle E-Business Suite 11i and Database - FAQ : Note: 285267.1
Is the Oracle E-Business Suite (Oracle Applications) certified against RAC?
Yes. (There is no seperate certification required for RAC.) ""
Can I use TAF with e-Business in a RAC environment?
TAF itself does not work with e-Business suite due to Forms/TAF limitations, but you can configure the tns failover clause. On instance failure, when the user logs back into the system, their session will be directed to a surviving instance, and the user will be taken to the navigator tab. Their committed work will be available; any uncommitted work must be re-started.
We also recommend you configure the forms error URL to identify a fallback middle tier server for Forms processes, if no router is available to accomplish switching across servers.
How to configure concurrent manager in a RAC environment?
Large clients commonly put the concurrent manager on a separate server now (in the middle tier) to reduce the load on the database server. The concurrent manager programs can be tied to a specific middle tier (e.g., you can have CMs running on more than one middle tier box). It is advisable to use specilize CM. CM middle tiers are set up to point to the appropriate database instance based on product module being used.
Should functional partitioning be used with Oracle Applications?
We do not recommend functional partitioning unless throughput on your server architecture demands it. Cache fusion has been optimized to scale well with non-partitioned workload.
If your processing requirements are extreme and your testing proves you must partition your workload in order to reduce internode communications, you can use Profile Options to designate that sessions for certain applications Responsibilities are created on a specific middle tier server. That middle tier server would then be configured to connect to a specific database instance.
To determine the correct partitioning for your installation you would need to consider several factors like number of concurrent users, batch users, modules used, workload characteristics etc.
Which e-Business version is prefereable?
Versions 11.5.5 onwards are certified with Oracle9i and hence with Oracle9i RAC. However we recommend the latest available version.
Can I use Automatic Undo Management with Oracle Applications?
Yes. In a RAC environment we highly recommend it.
Is Server Side Load Balancing supported/recommended/proven technology in Oracle EBusiness Suite?
Yes, Customers are using it successfully today. It is recommended to set up both Client and Server side load balancing. Note that the pieces coming from 8.0.6 home (forms and ccm), connections are directed to RAC instance based on the sequence its listed in the TNS entry description list and may not get load balanced optimally. For Oracle RAC 10.2 or higher do not set PREFER_LEAST_LOADED_NODE = OFF in your listener.ora, please set the CLB_GOAL on the service.
What are the maximum number of nodes under OCFS on Linux ?
Oracle 9iRAC on Linux, using OCFS for datafiles, can scale to a maximum of 32 nodes. According to the ** OCFS2 User Guide User Guide, OCFS 2 can support up to 255 nodes.
What files can I put on Linux OCFS?
For optimal performance, you should only put the following files on Linux OCFS:
- Datafiles
- Control Files
- Redo Logs
- Archive Logs
- SPFILE
Oracle Clusterware files OCR and Voting Disk can be put on OCFS2 however Best Practice is to put them on raw or block devices.
Where can I find documentation on OCFS ?
For Main Page >>> http://oss.oracle.com/projects/ocfs/ For User Manual >>> http://oss.oracle.com/projects/ocfs/documentation/ For OCFS Files >>> http://oss.oracle.com/projects/ocfs/files/supported/
What are the Best Practices for using a clustered file system with Oracle RAC?
Can I use a cluster file system for OCR, Voting Disk, Binaries as well as database files?
Oracle Best Practice for using Cluster File Systems (CFS) with Oracle RAC
* Oracle Clusterware binaries should not be placed on a CFS as this reduces cluster functionality while CFS is recovering, and also limits the ability to perform rolling upgrades of Oracle Clusterware.
* Oracle Clusterware voting disks and the Oracle Cluster Registry (OCR) should not be placed on a CFS as the I/O freeze during CFS reconfiguration can lead to node eviction, or cluster management activities to fail (I.E start, stop, or check of a resource).
* Oracle Database 10g binaries are supported on CFS for Oracle RAC 10g and for Oracle Database. The system should be configured to support multiple ORACLE_HOME’s in order to maintain the ability to perform a rolling patch application.
* Oracle Database 10g database files (e.g. datafiles, trace files, and archive log files) are supported on CFS.
Check Certify for certified cluster file systems.
Rolling Upgrades with Cluster File Systems in General
It is not recommended to use a cluster file system (CFS) for the Oracle Clusterware binaries. Oracle Clusterware supports in-place rolling upgrades. Using a shared Oracle Clusterware home results in a global outage during patch application and upgrades. A workaround is available to clone the Oracle Clusterware home for each upgrade. This is not common practice.
If a patch is marked for rolling upgrade, then it can be applied to a Oracle RAC database in a rolling fashion. Oracle supports rolling upgrades for the Oracle Database Automatic Storage Management (ASM) after you have upgraded to Oracle Database 11g. When using a CFS for the database and ASM Oracle homes, the CFS should be configured to use of context dependent links (CDSLs) or equivalent and these should configured to work in conjunction with rolling upgrades and downgrades. This includes updating the database and ASM homes in the OCR to point to the current home.
This is included in Metalink Note 444134.1
Can I use OCFS with SE Oracle RAC?
It is not supported to use OCFS with Standard Edition Oracle RAC. All database files must use ASM (redo logs, recovery area, datafiles, control files etc). You can not place binaries on OCFS as part of the SE Oracle RAC terms. We recommend that the binaries and trace files (non-ASM supported files) to be replicated on all nodes. This is done automatically by install.
Is Sun QFS supported with Oracle RAC? What about Sun GFS?
From certify, check there for the latest details.
Sun Cluster - Sun StorEdge QFS (9.2.0.5 and higher,10g and 10gR2):
No restrictions on placement of files on QFS
Sun StorEdge QFS is supported for Oracle binary executables, database data files, database data files, archive logs, Oracle Cluster Registry (OCR), Oracle Cluster ReadyServices voting disk and recovery area can be placed on QFS.
Solaris Volume Manager for Sun Cluster can be used for host-based mirroring
Supports up to 8 nodes
Is Red Hat GFS(Global File System) is certified by Oracle for use with Oracle Real Application Clusters?
Sistina Cluster Filesystem is not part of the standard RedHat kernel and therefore is not certified by Oracle but falls under a kernel extension. This however, does not mean that Oracle RAC is not certified with it. As a fact, Oracle RAC does not certify against a filesystem per se, but certifies against an operating system. If, as is the case with Sistina filesystem, the filesystem is certified with the operating system, this only means that the Oracle does not provide direct support and fix the filesystem in case of an error. Customer will have to contact the filesystem provider for support.
Is Linux OCFS2 (OCFS version 2) supported with Oracle RAC?
Yes See Certify for details on which platforms are supported.
What is the maximum number of nodes I can have in my cluster if I am using OCFS2?
Theroetically you can have up to 255 however it has been tested with up to 16 nodes.
Why is the home for Oracle Clusterware / Oracle Grid Infrastructure not recommended to be a subdirectory of the Oracle base directory?
If anyone other than root has write permissions to the parent directories of the Oracle Clusterware home / Oracle Grid Infrastructure for a Cluster home, then they can give themselves root escalations. This is a security issue.
Consequenely, it is strongly recommended to place the Oracle Grid Infrastructure / Oracle Clusterware home outside of the Oracle Base. The Oracle Universal Installer will confirm deviating settings during the Oracle Grid Infrastructure 11g Release 2 and later installation.
The Oracle Clusterware home itself is a mix of root and non-root permissions, as appropriate to the security requirements. Please, follow the installation guides regarding OS users and groups and how to structure the Oracle software installations on a given system.
Do I need to have user equivalence (ssh, etc...) set up after GRID/RAC is already installed?
Yes. Many assistants and scripts depend on user equivalence being set up.
With GNS, do ALL public addresses have to be DHCP managed (public IP, public VIP, public SCAN VIP)?
No, The choice to use DHCP for the public IPs is outside of Oracle. Oracle Clusterware and Oracle RAC will work with both static and DHCP assigned IP for the hostnames. When using GNS, Oracle Clusterwre will use DHCP for all VIPs in the cluster, which means node vips and SCAN vips.
How is the Oracle Cluster Registry (OCR) stored when I use ASM?
The OCR is stored similar to how Oracle Database files are stored. The extents are spread across all the disks in the diskgroup and the redundancy (which is at the extent leve) is based on the redundancy of the disk group. You can only have one OCR in a diskgroup. Best Practice for ASM is to have 2 diskgroups. Best Practice for OCR in ASM is to have a copy of the OCR in each diskgroup.
When does the Oracle node VIP fail over to another node and subsequently return to its home node?
The handling of the VIP with respect to a failover to another node and subsequent return to its home node is handled differently depending on the Oracle Clusterware version. In general, one can distinguish between Oracle Clusterware 10g & 11g Release 1 and Oracle Clusterware 11g Release 2 behavior.
For Oracle Clusterware 10g & 11g Release 1 the VIP will fail over to another node either after a network or a node failure. However, the VIP will automatically return to its home node only after a node failure and a subsequent restart of the node. Since the network is not constantly monitored in this Oracle Clusterware version, there is no way that Oracle Clusterware can detect the recovery of the network and initiate an automatic return of the node VIP to its home node.
Exception: With Oracle Patch Set 10.2.0.3 a new behavior was introduced that allowed the node VIP to return to its home node after the network recovered. The required network check was part of the database instance check. However, this new check introduced quite some side effects and hence, was disabled with subsequent bundle patches and the Oracle Patch Set 10.2.0.4
Starting with 10.2.0.4 and for Oracle Clusterware 11g Release 1 the default behavior is to avoid an automatic return of the node VIP to its home node after the network recovered. This behavior can be activated, if required, using the "ORA_RACG_VIP_FAILBACK" parameter. This parameter should only be used after reviewing support note 805969.1 (VIP does not relocate back to the original node starting from 10.2.0.4 and 11.1 even after the public network problem is resolved.)
With Oracle Clusterware 11g Release 2 the default behavior is to automatically initiate a return of the node VIP to its home node as soon as the network recovered after a failure. It needs to be noted that this behavior is not based on the parameter mentioned above and therefore does not induce the same side effects. Instead, a new network resource is used in Oracle Clusterware 11g Release 2, which monitors the network constantly, even after the network failed and the resource became "OFFLINE". This feature is called "OFFLINE resource monitoring" and is per default enabled for the network resource.
How do I protect the OCR and Voting in case of media failure?
In Oracle Database 10g Release 1 the OCR and Voting device are not mirrored within Oracle,hence both must be mirrored via a storage vendor method, like RAID 1.
Starting with Oracle Database 10g Release 2 Oracle Clusterware will multiplex the OCR and Voting Disk (two for the OCR and three for the Voting).
Please read Note: 279793.1 and Note: 268937.1 regarding backup and restore a lost Voting/OCR
How do I use multiple network interfaces to provide High Availability and/or Load Balancing for my interconnect with Oracle Clusterware?
This needs to be done externally to Oracle Clusterware usually by some OS provided nic bonding which gives Oracle Clusterware a single ip address for the interconnect but provide failover (High Availability) and/or load balancing across multiple nic cards. These solutions are provided externally to Oracle at a much lower level than the Oracle Clusterware, hence Oracle supports using them, the solutions are OS dependent and therefore the best source of information is from your OS Vendor. However, there are several articles in Metalink on how to do this. For example for Sun Solaris search for IPMP (IP network MultiPathing).
Note: Customer should pay close attention to the bonding setup/configuration/features and ensure their objectives are met, since some solutions provide only failover and some only loadbalancing still others claim to provide both. As always, it's always important to test your setup to ensure it does what it was designed to do.
Configure Redundant Network Cards / Switches for Oracle Database 10g Release 1 Real Application Cluster on Linux
When bonding with Network Interfaces that connect to separate switches (for redundancy) you must test if the NIC's are configured for active/active mode. The most reliable configuration for this architecture is to configure the NIC's for Active/Passive.
Can the Network Interface Card (NIC) device names be different on the nodes in a cluster, for both public and private?
All public NICs must have the same name on all nodes in the cluster
Similarly, all private NICs must also have the same names on all nodes
Do not mix NICs with different interface types (infiniband, ethernet, hyperfabric, etc.) for the same subnet/network.
Can I run a 10.1.0.x database with Oracle Clusterware 10.2 ?
Yes. Oracle Clusterware 10.2 will support both 10.1 and 10.2 databases (and ASM too!). A detailed matrix is available in Note: 337737.1
What do I do, I have a corrupt OCR and no valid backup?
Note: 428682.1 describes how to recreate your OCR/Voting Disk which you have accidently deleted and cannot recover from backups
Is it supported to rerun root.sh from the Oracle Clusterware installation ?
For Oracle RAC 10g rerunning root.sh after the initial successful install of the Oracle Clusterware is expressly discouraged and unsupported. We strongly recommend not doing it.
In case where root.sh is failing to execute for on an initial install (or a new node joining an existing cluster), it is OK to re-run root.sh after the cause of the failure is corrected (permissions, paths, etc.). In this case, please run rootdelete.sh to undo the local effects of root.sh before re-running root.sh.
When ct run the command 'onsctl start' receives the message "Unable to open libhasgen10.so". Any idea why the message "unable to open libhasgen10.so" ?
Most likely you are trying to start ONS from ORACLE_HOME instead of Oracle Clusterware (or Grid Infrastructure in 11.2) home. Please try to start it from the Oracle Clusterware home.
Voting Files stored in ASM - How many disks per disk group do I need?
If Voting Files are stored in ASM, the ASM disk group that hosts the Voting Files will place the appropriate number of Voting Files in accordance to the redundancy level. Once Voting Files are managed in ASM, a manual addition, deletion, or replacement of Voting Files will fail, since users are not allowed to manually manage Voting Files in ASM.
If the redundancy level of the disk group is set to "external", 1 Voting File is used.
If the redundancy level of the disk group is set to "normal", 3 Voting Files are used.
If the redundancy level of the disk group is set to "high", 5 Voting Files are used.
Note that Oracle Clusterware will store the disk within a disk group that holds the Voting Files. Oracle Clusterware does not rely on ASM to access the Voting Files.
In addition, note that there can be only one Voting File per failure group. In the above list of rules, it is assumed that each disk that is supposed to hold a Voting File resides in its own, dedicated failure group.
In other words, a disk group that is supposed to hold the above mentioned number of Voting Files needs to have the respective number of failure groups with at least one disk. (1 / 3 / 5 failure groups with at least one disk)
Consequently, a normal redundancy ASM disk group, which is supposed to hold Voting Files, requires 3 disks in separate failure groups, while a normal redundancy ASM disk group that is not used to store Voting Files requires only 2 disks in separate failure groups.
OCR stored in ASM - What happens, if my ASM instance fails on a node?
If an ASM instance fails on any node, the OCR becomes unavailable on this particular node, but the node remains operational.
If the (RAC) databases use ASM, too, they cannot access their data on this node anymore during the time the ASM instance is down. If a RAC database is used, access to the same data can be established from another node.
If the CRSD process running on the node affected by the ASM instance failure is the OCR writer, AND the majority of the OCR locations is stored in ASM, AND an IO is attempted on the OCR during the time the ASM instance is down on this node, THEN CRSD stops and becomes inoperable. Hence cluster management is affected on this particular node.
Under no circumstances will the failure of one ASM instance on one node affect the whole cluster.
Is it possible to use ASM for the OCR and voting disk?
Yes. As of Oracle Real Application Clusters 11g Release 2, the OCR and Voting Disks can be stored in ASM. This is the recommended best practice for this release.
For releases prior to 11g Release 2, the OCR and voting disk must be on RAW devices or CFS (cluster filesystem).
RAW devices (or block devices on Linux) is the best practice for Oracle RAC 10g or Oracle RAC 11g Release 1.
I am trying to move my voting disks from one diskgroup to another and getting the error "crsctl replace votedisk – not permitted between ASM Disk Groups." Why?
You need to review the ASM and crsctl logs to see why the command is failing.
To put your voting disks in ASM, you must have the diskgroup set up properly. There must be enough failure groups to support the redundancy of the voting disks as set by the redundancy on the disk group. EG: Normal redundancy, 3 failure groups are requried, High redundancy, 5 failure groups. Note: by default each disk in a diskgroup is put in its own failure group. The compatible.asm attribute of the diskgroup must be set to 11.2 and you must be using 11.2 version of Oracle Clusterware and ASM.
Can I run the fixup script generated by the 11.2 OUI or CVU on a running system?
It depends on what the problem that were listed to be fixed. The fixup scripts can change system parameters so you should not change system parameters while applications are running. However, if an earlier version of Oracle Database is already running on the system, there should not be any need to change the system parameters.
What should the permissions be set to for the voting disk and ocr when doing an Oracle RAC Install?
The Oracle Real Application Clusters install guide is correct. It describes the PRE-INSTALL ownership/permission requirements for ocr and voting disk. This step is needed to make sure that the Oracle Clusterware install succeeds. Please don't use those values to determine what the ownership/permmission should be POST INSTALL. The root script will change the ownership/permission of ocr and voting disk as part of install. The POST INSTALL permissions will end up being : OCR - root:oinstall - 640 Voting Disk - oracle:oinstall - 644
How to move the OCR location ?
For Oracle RAC 10g Release 1
- stop the CRS stack on all nodes using "init.crs stop"
- Edit /var/opt/oracle/ocr.loc on all nodes and set up ocrconfig_loc=new OCR device
- Restore from one of the automatic physical backups using ocrconfig -restore.
- Run ocrcheck to verify.
- reboot to restart the CRS stack.
For Oracle RAC 10g Release 2 or later Please use the OCR command to replace the OCR with the new location:
# ocrconfig -replace ocr /dev/newocr
# ocrconfig -replace ocrmirror /dev/newocrmirror
Manual editing of ocr.loc or equivalent is not recommended, and will not work.
With Oracle Clusterware 10g, how do you backup the OCR?
There is an automatic backup mechanism for OCR. The default location is : $ORA_CRS_HOME\cdata\"clustername"\
To display backups :
#ocrconfig -showbackup
To restore a backup :
#ocrconfig -restore
The automatic backup mechanism keeps up to about a week old copy. So, if you want to retain a backup copy more than that, then you should copy that "backup" file to some other name.
Unfortunately with Oracle RAC 10g Release 1 there are a couple of bugs regarding backup file manipulation, and changing default backup dir on Windows. These were fixed in 10.1.0.4. OCR backup on Windows are absent. Only file in the backup directory is temp.ocr which would be the last backup. You can restore this most recent backup by using the command ocr -restore temp.ocr
With Oracle RAC 10g Release 2 or later, you can also use the export command:
#ocrconfig -export -s online, and use -import option to restore the contents back.
With Oracle RAC 11g Release 1, you can do a manaual backup of the OCR with the command:
# ocrconfig -manualbackup
I am trying to install Oracle Clusterware (10.2) and when I run the OUI, at the Specify Cluster Configuration screen, the Add, Edit and Remove buttons are grayed out. Nothing comes up in the cluster nodes either. Why?
Check for 3rd Party Vendor clusterware (such as Sun Cluster or Veritas Cluster) that was not completely removed. IE Look for /opt/ORCLcluster directory, it should be removed.
What happens if I lose my voting disk(s)?
If you lose 1/2 or more of all of your voting disks, then nodes get evicted from the cluster, or nodes kick themselves out of the cluster. It doesn't threaten database corruption. Alternatively you can use external redundancy which means you are providing redundancy at the storage level using RAID.
For this reason when using Oracle for the redundancy of your voting disks, Oracle recommends that customers use 3 or more voting disks in Oracle RAC 10g Release 2. Note: For best availability, the 3 voting files should be physically separate disks. It is recommended to use an odd number as 4 disks will not be any more highly available than 3 disks, 1/2 of 3 is 1.5...rounded to 2, 1/2 of 4 is 2, once we lose 2 disks, our cluster will fail with both 4 voting disks or 3 voting disks.
Restoring corrupted voting disks is easy since there isn't any significant persistent data stored in the voting disk. See the Oracle Clusterware Admin and Deployment Guide for information on backup and restore of voting disks.
I am installing Oracle Clusterware with a 3rd party vendor clusterware however in the "Specify Cluster Configuration Page" , Oracle Clusterware installer doesn't show the existing nodes. Why?
This shows that Oracle Clusterware does not detect the 3rd Party clusterware is installed. Make sure you have followed the installation instructions provided by the vendor for integrating with Oracle RAC. Make sure LD_LIBRARY_PATH is not set.
For example with Sun Cluster, make sure the libskgxn* files to the /opt/ORCLcluster directory. Check that lsnodes returns the correct list of nodes in the Sun Cluster.
I made a mistake when I created the VIP during the install of Oracle Clusterware, can I change the VIP?
Yes The details of how to do this are described in Metalink Note.276434.1
How should I test the failure of the public network (IE Oracle VIP failover) in my Oracle RAC environment?
Prior to 10.2.0.3, It was possible to test VIP failover by simply running
ifconfig
down.
The intended behaviour was that the VIP would failover to the another node. In 10.2.0.3 this is the same behaviour on Linux, however on other operating systems the VIP will NOT failover, instead the interface will be plumbed again. To test VIP failover on platforms other than Linux, the switch can be turned off or the physical cable pulled.
The is best way to test. NOTE: if you have other DB’s that share the same IP’s then they will be affected. Your tests should simulate Production failures which are generally Switch errors or interface errors.
What is the voting disk used for?
A voting disk is a backup communications mechanism that allows CSS daemons to negotiate which sub-cluster will survive. These voting disks keep a status of who is currently alive and counts votes in case of a cluster reconfiguration. It works as follows:
a) Ensures that you cannot join the cluster if you cannot access the voting disk(s)
b) Leave the cluster if you cannot communicate with it (to ensure we do not have aberrant nodes)
c) Should multiple sub-clusters form, it will only allow one to continue. It prefers a greater number of nodes, and secondly the node with the lowest incarnation number.
d) Is kept redundant by Oracle in 10g Release 2 (you need to access a majority of existing voting disks)
At most only one sub-cluster will continue and a split brain will be avoided.
Can I configure a firewall (iptables) on the cluster interconnect?
Disable all firewalls on the cluster interconnect. See note: 554781.1 for details.
Can I change the public hostname in my Oracle Database 10g Cluster using Oracle Clusterware?
Hostname changes are not supported in Oracle Clusterware (CRS), unless you want to perform a deletenode followed by a new addnode operation.
The hostname is used to store among other things the flag files and Oracle Clusterware stack will not start if hostname is changed.
Does the hostname have to match the public name or can it be anything else?
When there is no vendor clusterware, only Oracle Clusterware, then the public node name must match the host name. When vendor clusterware is present, it determines the public node names, and the installer doesn't present an opportunity to change them. So, when you have a choice, always choose the hostname.
I have a 2-node RAC running. I notice that it is always node2 that is evicted when I test private network failure scenario by disconnecting the private network cable. Doesn't matter whether it is node1's or node2's private network cable that is disconnected, it is always the node2 that is evicted. What happens in a 3-nodes RAC cluster if node1's cable is disconnected?
The node with the lower node number will survive(The first node to join the cluster). In case of 3 nodes, 2 nodes will survive and the one you pulled the cable will go away. 4 nodes - the sub cluster with the lower node number will survive.
Can I use Oracle Clusterware to provide cold failover of my single instance Oracle Databases?
Oracle does not provide the necessary wrappers to fail over single-instance databases using Oracle Clusterware. It's possible for customers to use Oracle Clusterware to wrap arbitrary applications, it'd be possible for them to wrap single-instance databases this way. A sample can be found in the DEMOs that are distributed with Oracle Database 11g.
What are the licensing rules for Oracle Clusterware? Can I run it without RAC?
Check the Oracle® Database Licensing Information 11g Release 1 (11.1) Part Number B28287-01 Look in the Special Use section under Oracle Database Editions.
In the course of failure testing in an extended RAC environment we find entries in the cssd logfile which indicate actions like 'diskShortTimeout set to (value)' and 'diskLongTimeout set to (value)'.
Can anyone please explain the meaning of these two timeouts in addition to disktimeout?
Having a short and long disktimeout, and no longer just one disktimeout, is due to patch for bug 4748797 (included in 10.2.0.2). The long disktimeout is 200 sec by default unless set differently via 'crsctl set css disktimeout', and applies to time outside a reconfiguration. The short disktimeout is in effect during a reconfiguration and is misscount-3s. The point is that we can tolerate a long disktimeout when all nodes are just running fine, but have to revert back to a short disktimeout if there's a reconfiguration.
During Oracle Clusterware installation, I am asked to define a private node name, and then on the next screen asked to define which interfaces should be used as private and public interfaces. What information is required to answer these questions?
The private names on the first screen determine which private interconnect will be used by CSS.
Provide exactly one name that maps to a private IP address, or just the IP address itself. If a logical name is used, then the IP address this maps to can be changed subsequently, but if you IP address is specified CSS will always use that IP address. CSS cannot use multiple private interconnects for its communication hence only one name or IP address can be specified.
The private interconnect enforcement page determines which private interconnect will be used by the RAC instances.
It's equivalent to setting the CLUSTER_INTERCONNECTS init.ora parameter, but is more convenient because it is a cluster-wide setting that does not have to be adjusted every time you add nodes or instances. RAC will use all of the interconnects listed as private in this screen, and they all have to be up, just as their IP addresses have to be when specified in the init.ora paramter. RAC does not fail over between cluster interconnects; if one is down then the instances using them won't start.
Can I change the name of my cluster after I have created it when I am using Oracle Clusterware?
No, you must properly deinstall Oracle Clusterware and then re-install. To properly de-install Oracle Clusterware, you MUST follow the directions in the Installation Guide Chapter 10. This will ensure the ocr gets cleaned out.
Which processes access the OCR ?
Oracle Cluster Registry (OCR) is used to store the cluster configuration information among other things. OCR needs to be accessible from all nodes in the cluster. If OCR became inaccessible the CSS daemon would soon fail, and take down the node. PMON never needs to write to OCR. To confirm if OCR is accessible, try ocrcheck from your ORACLE_HOME and ORA_CRS_HOME.
Why does Oracle Clusterware use an additional 'heartbeat' via the voting disk, when other cluster software products do not?
Oracle uses this implementation because Oracle clusters always have access to a shared disk environment. This is different from classical clustering which assumes shared nothing architectures, and changes the decision of what strategies are optimal when compared to other environments. Oracle also supports a wide variety of storage types, instead of limiting it to a specific storage type (like SCSI), allowing the customer quite a lot of flexibility in configuration.
Why does Oracle still use the voting disks when other cluster sofware is present?
Voting disks are still used when 3rd party vendor clusterware is present, because vendor clusterware is not able to monitor/detect all failures that matter to Oracle Clusterware and the database. For example one known case is when the vendor clusterware is set to have its heartbeat go over a different network than RAC traffic. Continuing to use the voting disks allows CSS to resolve situations which would otherwise end up in cluster hangs.
Customer is hitting bug 4462367 with an error message saying low open file descriptor, how do I work around this until the fix is released with the Oracle Clusterware Bundle for 10.2.0.3 or 10.2.0.4 is released?
The fix for "low open file descriptor" problem is to increase the ulimit for Oracle Clusterware. Please be careful when you make this type of change and make a backup copy of the init.crsd before you start! To do this, you can modify the init.crsd as follows, while you wait for the patch: 1. Stop Oracle Clusterware on the node (crsctl stop crs)
2. copy the /etc/init.d/init.crsd
3. Modify the file changing:
# Allow the daemon to drop a diagnostic core file/
ulimit -c unlimited
ulimit -n unlimited
to
# Allow the daemon to drop a diagnostic core file/
ulimit -c unlimited
ulimit -n 65536
4. restart Oracle Clusterware in the node (crsctl start crs)
How do I identify the voting file location ?
Run the following command from /bin
"crsctl query css votedisk"
How much I/O activity should the voting disk have?
Approximately 2 read + 1 write per second per node.
Does Oracle Clusterware have to be the same or higher release than all instances running on the cluster?
Yes - Oracle Clusterware must be the same or a higher release with regards to the RDBMS or ASM Homes.
Please refer to Note#337737.1
Can I use Oracle Clusterware to monitor my EM Agent?
Check out Chapter 3 of the EM advanced configuration guide, specifically the section on active passive configuration of agents. You should be able to model those to your requirements. There is nothing special about the commands, but you do need to follow the startup/shutdown sequence to avoid any discontinuity of monitoring. The agent does start a watchdog that monitors the health of the actual monitoring process. This is done automatically at agent start. Therefore you could use Oracle Clusterware but you should not need to.
My customer has noticed tons of log files generated under $CRS_HOME/log//client, is there any way automated way we can setup through Oralce Clusterware to prevent/minimize/remove those aggressively generated files?
Check Note.5187351.8 You can either apply the patchset if it is available for your platform or have a cron job that removes these files until the patch is available.
What are the IP requirements for the private interconnect?
The install guide will tell you the following requirements private IP address must satisfy the following requirements:
1. Must be separate from the public network
2. Must be accessible on the same network interface on each node
3. Must have a unique address on each node
4. Must be specified in the /etc/hosts file on each node
The Best Pratices recommendation is to use the TCP/IP standard for non-routeable networks. Reserved address ranges for private (non-routed) use (see TCP/IP RFC 1918):
* 10.0.0.0 -> 10.255.255.255
* 172.16.0.0 -> 172.31.255.255
* 192.168.0.0 -> 192.168.255.255
Cluvfy will give you an error if you do not have your private interconnect in the ranges above.
You should not ignore this error. If you are using an IP address in the range used for the public network for the private network interfaces, you are pretty much messing up the IP addressing, and possibly the routing tables, for the rest of the corporation. IP addresses are a sparse commodity, use them wisely. If you use them on a non-routable network, there is nothing to prevent someone else to go and use them in the normal corporate network, and then when those RAC nodes find out that there is another path to that address range (through RIP), they just might start sending traffic to those other IP addresses instead of the interconnect. This is just a bad idea.
Can I set up failover of the VIP to another card in the same machine or what do I do if I have different network interfaces on different nodes in my cluster (I.E. eth0 on node1,2 and eth1 on node 3,4)?
With srvctl, you can modify the nodeapp for the VIP to list the NICs it can use. Then VIP will try to start on eth0 interface and if it fails, try eth1 interface.
./srvctl modify nodeapps -n -A //eth0\
eth1
Note how the interfaces are a list separated by the ‘
’ symbol and how you need to quote this with a ‘\’ character or the Unix shell will interpret the character as a ‘pipe’. So on a node called ukdh364 with a VIP address of ukdh364vip and we want a netmask (say) of 255.255.255.0 then we have:
./srvctl modify nodeapps -n ukdh364 -A ukdh364vip/255.255.255.0/eth0\
eth1
To check which interfaces are configured as public or private use oifcfg getif
example output:
eth0 138.2.238.0 global public
eth1 138.2.240.0 global public
eth2 138.2.236.0 global cluster_interconnect
An ifconfig on your machine will show what the hardware names for the interface cards installed.
How to Restore a Lost Voting Disk used by Oracle Clusterware 10g
Please read Note:279793.1 and for OCR Note:268937.1
As long as you can confirm via the CSS daemon logfile that it thinks the voting disk is bad, you can restore the voting disk from backup while the cluster is online. This is the backup that you took with dd (by the manual's request) after the most recent addnode, deletenode, or install operation. If by accident you restore a voting disk that the CSS daemon thinks is NOT bad, then the entire cluster will probably go down.
crsctl add css votedisk - adds a new voting disk
crsctl delete css votedisk - removes a voting disk
Note: the cluster has to be down. You can also restore the backup via dd when the cluster is down.
How can I register the listener with Oracle Clusterware in RAC 10g Release 2?
NetCA is the only tool that configures listener and you should be always using it. It will register the listener with Oracle Clusterware. There are no other supported alternatives.
How is the voting disk used by Oracle Clusterware?
The voting disk is accessed exclusively by CSS (one of the Oracle Clusterware daemons). This is totally different from a database file. The database looks at the database files and interacts with the CSS daemon (at a significantly higher level conceptually than any notion of "voting disk").
"Non-synchronized access" (i.e. database corruption) is prevented by ensuring that the remote node is down before reassigning its locks. The voting disk, network, and the control file are used to determine when a remote node is down, in different, parallel, indepdendent ways that allow each to provide additional protection compared to the other. The algorithms used for each of these three things are quite different.
As far as voting disks are concerned, a node must be able to access strictly more than half of the voting disks at any time. So if you want to be able to tolerate a failure of n voting disks, you must have at least 2n+1 configured. (n=1 means 3 voting disks). You can configure up to 32 voting disks, providing protection against 15 simultaneous disk failures, however it's unlikely that any customer would have enough disk systems with statistically independent failure characteristics that such a configuration is meaningful. At any rate, configuring multiple voting disks increases the system's tolerance of disk failures (i.e. increases reliability).
Configuring a smaller number of voting disks on some kind of RAID system can allow a customer to use some other means of reliability than the CSS's multiple voting disk mechanisms. However there seem to be quite a few RAID systems that decide that 30-60 second (or 45 minutes in the case of veritas) IO latencies are acceptable. However we have to wait for at least the longest IO latency before we can declare a node dead and allow the database to reassign database blocks. So while using an independent RAID system for the voting disk may appear appealing, sometimes there are failover latency consequenecs.
Does Oracle Clusterware support application vips?
Yes, with Oracle Database 10g Release 2, Oracle Clusterware now supports an "application" vip. This is to support putting applications under the control of Oracle Clusterware using the new high availability API and allow the user to use the same URL or connection string regardless of which node in the cluster the application is running on. The application vip is a new resource defined to Oracle Clusterware and is a functional vip. It is defined as a dependent resource to the application. There can be many vips defined, typically one per user application under the control of Oracle Clusterware. You must first create a profile (crs_profile), then register it with Oracle Clusterware (crs_register). The usrvip script must run as root.
How do I put my application under the control of Oracle Clusterware to achieve higher availability?
First write a control agent. It must accept 3 different parameters: start-The control agent should start the application, check-The control agent should check the application, stop-The Control agent should start the application. Secondly you must create a profile for your application using crs_profile. Thirdly you must register your application as a resource with Oracle Clusterware (crs_register). See the RAC Admin and Deployment Guide for details.
Is it supported to allow 3rd Party Clusterware to manage Oracle resources (instances, listeners, etc) and turn off Oracle Clusterware management of these?
In 10g we do not support using 3rd Party Clusterware for failover and restart of Oracle resources. Oracle Clusterware resources should not be disabled.
What is the High Availability API?
An application-programming interface to allow processes to be put under the High Availability infrastructure that is part of the Oracle Clusterware distributed with Oracle Database 10g. A user written script defines how Oracle Clusterware should start, stop and relocate the process when the cluster node status changes. This extends the high availability services of the cluster to any application running in the cluster. Oracle Database 10g Real Application Clusters (RAC) databases and associated Oracle processes (E.G. listener) are automatically managed by the clusterware.
Is it a requirement to have the public interface linked to ETH0 or does it only need to be on a ETH lower than the private interface?: - public on ETH1 - private on ETH2
There is no requirement for interface name ordering. You could have - public on ETH2 - private on ETH0 Just make sure you choose the correct public interface in VIPCA, and in the installer's interconnect classification screen.
How do I restore OCR from a backup? On Windows, can I use ocopy?
The only recommended way to restore an OCR from a backup is "ocrconfig -restore ". The ocopy command will not be able to perform the restore action for OCR.
What are the network requirements for an extended RAC cluster?
Necessary Connections
Interconnect, SAN, and IP Networking need to be kept on separate channels, each with required redundancy. Redundant connections must not share the same Dark Fiber (if used), switch, path, or even building entrances. Keep in mind that cables can be cut.
The SAN and Interconnect connections need to be on dedicated point-to-point connections. No WAN or Shared connection allowed. Traditional cables are limited to about 10 km if you are to avoid using repeaters. Dark Fiber networks allow the communication to occur without repeaters. Since latency is limited, Dark Fiber networks allow for a greater distance in separation between the nodes. The disadvantage of Dark Fiber networks are they can cost hundreds of thousands of dollars, so generally they are only an option if they already exist between the two sites.
If direct connections are used (for short distances) this is generally done by just stringing long cables from a switch. If a DWDM or CWDM is used then then these are directly connected via a dedicated switch on either side.
Note of caution: Do not do RAC Interconnect over a WAN. This is a the same as doing it over the public network which is not supported and other uses of the network (i.e. large FTPs) can cause performance degradations or even node evictions.
For SAN networks make sure you are using SAN buffer credits if the distance is over 10km.
If Oracle Clusterware is being used, we also require that a single subnet be setup for the public connections so we can fail over VIPs from one side to another.
Can a customer use SE RAC to implement an "Extended RAC Cluster" ?
YES. Effective with 11g Rel.1 the former restriction to have all nodes co-located in one room when using SE RAC has been lifted. Customers can now use SE RAC clusters in extended environments. However, other SE RAC restrictions still apply (e.g. compulsory usage of ASM, no third party cluster nor volume manager must be installed). Please, refer to the licensing documentation for more information.
What is the maximum distance between nodes in an extended RAC environment?
The high impact of latency create practical limitations as to where this architecture can be deployed. While there is not fixed distance limitation, the additional latency on round trip on I/O and a one way cache fusion will have an affect on performance as distance increases. For example tests at 100km showed a 3-4 ms impact on I/O and 1 ms impact on cache fusion, thus the farther distance is the greater the impact on performance. This architecture fits best where the 2 datacenters are relatively close (<~25km) and the impact is negligible. Most customers implement under this distance w/ only a handful above and the farthest known example is at 100km. Largest distances than the commonly implemented may want to estimate or measure the performance hit on their application before implementing. Due ensure a proper setup of SAN buffer credits to limit the impact of distance at the I/O layer.
Can I use ASM as mechanism to mirror the data in an Extended RAC cluster?
Yes, but it cannot replicate everything that needs replication.
ASM works well to replicate any object you can put in ASM. But you cannot put the OCR or Voting Disk in ASM.
In 10gR1 they can either be mirrored using a different mechanism (which could then be used instead of ASM) or the OCR needs to be restored from backup and the Voting Disk can be recreated.
In the future we are looking at providing Oracle redundancy for both.
How should voting disks be implemented in an extended cluster environment? Can I use standard NFS for the third site voting disk?
http://www.oracle.com/technology/products/database/clustering/pdf/thirdvoteonnfs.pdf Standard NFS is only supported for the tie-breaking voting disk in an extended cluster environment. See platform and mount option restrictions at: http://www.oracle.com/technology/products/database/clustering/pdf/thirdvoteonnfs.pdf Otherwise just as with database files, we only support voting files on certified NAS devices, with the appropriate mount options. Pls refer to Metalink Note 359515.1 for a full description of the required mount options. For a complete list of supported NAS vendors refer to OTN at: http://www.oracle.com/technology/deploy/availability/htdocs/vendors_nfs.html
Can I use ASM to mirror Oracle data in an extended RAC environment?
This support is for 10gR2 onwards and has the following limitations:
1. As in any extended RAC environments, the additional latency induced by distance will affect I/O and cache fusion performance. This effect will vary by distance and the customer is responsible for ensuring that the impact attained in their environment is acceptable for their application.
2. OCR must be mirrored across both sites using Oracle provided mechanisms.
3. Voting Disk redundancy must exists across both sites, and at a 3rd site to act as an arbitrage. This third site may be via a WAN.
4. Storage at each site much be setup as seperate failure groups and use ASM mirroring, to ensure at least one copy of the data at each site.
5. Customer must have a seperate and dedicated test cluster also in an extended configuration setup using the same software and hardware components (can be fewer or smaller nodes).
6. Customer must be aware that in 10gR2 ASM does not provide partial resilvering. Should a loss of connectivity between the sites occur, one of the failure groups will be marked invalid. When the site rejoins the cluster, the failure groups will need to be manually dropped and added.
Where can I find the CVU trace files?
CVU log files can be found under $CV_HOME/cv/log directory. The log files are automatically rotated and the latest log file has the name cvutrace.log.0. It is a good idea to clean up unwanted log files or archive them to reclaim disk place.
In recent releases, CVU trace files are generated by default. Setting SRVM_TRACE=false before invoking cluvfy disables the trace generation for that invocation.
Why is validateUserEquiv failing during install (or cluvfy run)?
SSH must be set up as per the pre-installation tasks. It is also necessary to have file permissions set as described below for features such as Public Key Authorization to work. If your permissions are not correct, public key authentication will fail, and will fallback to password authentication with no helpful message as to why. The following server configuration files and/or directories must be owned by the account owner or by root and GROUP and WORLD WRITE permission must be disabled.
$HOME
$HOME/.rhosts
$HOME/.shosts
$HOME/.ssh
$HOME/.ssh.authorized-keys
$HOME/.ssh/authorized-keys2 #Openssh specific for ssh2 protocol.
SSH (from OUI) will also fail if you have not connected to each machine in your cluster as per the note in the installation guide:
The first time you use SSH to connect to a node from a particular system, you may see a message similar to the following:
The authenticity of host 'node1 (140.87.152.153)' can't be established. RSA key fingerprint is 7z:ez:e7:f6:f4:f2:4f:8f:9z:79:85:62:20:90:92:z9.
Are you sure you want to continue connecting (yes/no)?
Enter
yes
at the prompt to continue. You should not see this message again when you connect from this system to that node. Answering yes to this question causes an entry to be added to a "known-hosts" file in the .ssh directory which is why subsequent connection requests do not re-ask.
This is known to work on Solaris and Linux but may work on other platforms as well.
How do I turn on tracing?
Set the environmental variable SRVM_TRACE to true. For example, in tcsh "setenv SRVM_TRACE true" will turn on tracing. Also it may help to run cluvfy with -verbose attribute
$script run.log
$export SRVM_TRACE=TRUE
$cluvfy -blah -verbose
$exit
Can I check if the storage is shared among the nodes?
Yes, you can use 'comp ssa' command to check the sharedness of the storage. Please refer to the known issues section for the type of storage supported by cluvfy.
When I run 10.2 CLUVFY on a system where RAC 10g Release 1 is running I get following output:
Package existence check failed for "SUNWscucm:3.1".
Package existence check failed for "SUNWudlmr:3.1".
Package existence check failed for "SUNWudlm:3.1".
Package existence check failed for "ORCLudlm:Dev_Release_06/11/04,_64bit_3.3.4.8_reentrant".
Package existence check failed for "SUNWscr:3.1".
Package existence check failed for "SUNWscu:3.1".
Checking this Solaris system I don't see those packages installed. Can I continue my install?
Note that cluvfy checks all possible prerequisites and tells you whether your system passes the check or not. You can then cross reference with the install guide to see if the checks that failed are required for your type of installation. It the above case, if you are not planning on using Sun Cluster, then you can continue the install. The checks that failed are the checks for Sun Cluster required packages and are not neede d on your cluster. As long as everything else checks out successfully, you can continue.
What are the default values for the command line arguments?
Here are the default values and behavior for different stage and component commands:
For component nodecon:
If no -i or -a arguments is provided, then cluvfy will get into the discovery mode.
For component nodereach:
If no -srcnode is provided, then the local(node of invocation) will be used as the source node.
For components cfs, ocr, crs, space, clumgr:
If no -n argument is provided, then the local node will be used.
For components sys and admprv:
If no -n argument is provided, then the local node will be used.
If no -osdba argument is provided, then 'dba' will be used. If no -orainv argument is provided, then 'oinstall' will be used.
For component peer:
If no -osdba argument is provided, then 'dba' will be used.
If no -orainv argument is provided, then 'oinstall' will be used.
For stage -post hwos:
If no -s argument is provided, then cluvfy will get into the discovery mode.
For stage -pre clusvc:
If no -c argument is provided, then cluvfy will skip OCR related checks.
If no -q argument is provided, then cluvfy will skip voting disk related checks.
If no -osdba argument is provided, then 'dba' will be used.
If no -orainv argument is provided, then 'oinstall' will be used.
For stage -pre dbinst:
If -cfs_oh flag is not specified, then cluvfy will assume Oracle home is not on a shared file system.
If no -osdba argument is provided, then 'dba' will be used.
If no -orainv argument is provided, then 'oinstall' will be used.
How do I check the Oracle Clusterware stack and other sub-components of it?
Cluvfy provides commands to check a particular sub-component of the CRS stack as well as the whole CRS stack. You can use the 'comp ocr' command to check the integrity of OCR. Similarly, you can use 'comp crs' and 'comp clumgr' commands to check integrity of crs and clustermanager sub-components. To check the entire CRS stack, run the stage command 'clucvy stage -post crsinst'.
Is there a way to verify that the Oracle Clusterware is working properly before proceeding with RAC install?
Yes. You can use the post-check command for cluster services setup(-post clusvc) to verify CRS status. A more appropriate test would be to use the pre-check command for database installation(-pre dbinst). This will check whether the current state of the system is suitable for RAC install.
At what point cluvfy is usable? Can I use cluvfy before installing Oracle Clusterware?
You can run cluvfy at any time, even before CRS installation. In fact, cluvfy is designed to assist the user as soon as the hardware and OS is up. If you invoke a command which requires CRS or RAC on local node, cluvfy will report an error if those required products are not yet installed.
What is CVU? What are its objectives and features?
CVU brings ease to RAC users by verifying all the important components that need to be verified at different stages in a RAC environment. The wide domain of deployment of CVU ranges from initial hardware setup through fully operational cluster for RAC deployment and covers all the intermediate stages of installation and configuration of various components. The command line tool is cluvfy. Cluvfy is a non-intrusive utility and will not adversely affect the system or operations stack.
What is a stage?
CVU supports the notion of Stage verification. It identifies all the important stages in RAC deployment and provides each stage with its own entry and exit criteria. The entry criteria for a stage define a specific set of verification tasks to be performed before initiating that stage. This pre-check saves the user from entering into a stage unless its pre-requisite conditions are met. The exit criteria for a stage define another specific set of verification tasks to be performed after completion of the stage. The post-check ensures that the activities for that stage have been completed successfully. It identifies any stage specific problem before it propagates to subsequent stages; thus making it difficult to find its root cause. An example of a stage is "pre-check of database installation", which checks whether the system meets the criteria for RAC install.
What is a component?
CVU supports the notion of Component verification. The verifications in this category are not associated with any specific stage. The user can verify the correctness of a specific cluster component. A component can range from a basic one, like free disk space to a complex one like CRS Stack. The integrity check for CRS stack will transparently span over verification of multiple sub-components associated with CRS stack. This encapsulation of a set of tasks within specific component verification should be of a great ease to the user.
What is nodelist?
Nodelist is a comma separated list of hostnames without domain. Cluvfy will ignore any domain while processing the nodelist. If duplicate entities after removing the domain exist, cluvfy will eliminate the duplicate names while processing. Wherever supported, you can use '-n all' to check on all the cluster nodes. Check this for more information on nodelist and shortcuts.
Do I have to be root to use CVU?
No. CVU is intended for database and system administrators. CVU assumes the current user as oracle user.
What about discovery? Does CVU discover installed components?
At present, CVU discovery is limited to these components. CVU discovers available network interfaces if you do not specify any interface or IP address in its command line. For storage related verification, CVU discovers all the supported storage types if you do not specify a particular storage. CVU discovers CRS HOME if one is available.
What are the requirements for CVU?
CVU requires: 1._ An area with at least 30MB for containing software bits on the invocation node. 2._ Java 1.4.1 location on the invocation node. 3._ A work directory with at least 25MB on all the nodes. CVU will attempt to copy the necessary bits as required to this location. Make sure, the location exists on all nodes and it has write permission for CVU user. This dir is set through the CV_DESTLOC environment variable. If this variable does not exist, CVU will use "/tmp" as the work dir. 4._ On RedHat Linux 3.0, an optional package 'cvuqdisk' is required on all the nodes. This assists CVU in finding scsi disks and helps CVU to perform storage checks on disks. Please refer to What is 'cvuqdisk' rpm? for detail. Note that, this package should be installed only on RedHat Linux 3.0 distribution.
What is 'cvuqdisk' rpm? Why should I install this rpm?
CVU requires root privilege to gather information about the scsi disks during discovery. A small binary uses the setuid mechanism to query disk information as root. Note that this process is purely a read-only process with no adverse impact on the system. To make this secured, this binary is packaged in the cvuqdisk rpm and need root privilege to install on a machine. If this package is installed on all the nodes, CVU will be able to perform discovery and shared storage accessibility checks for scsi disks. Otherwise, it complains about the missing package 'cvuqdisk'. Note that, this package should be installed only on RedHat Linux 3.0 distribution. Discovery of scsi disks for RedHat Linux 2.1 is not supported.
How do I install 'cvuqdisk' package?
Here are the steps to install cvuqdisk package. 1._ Become root user 2._ Copy the rpm ( cvuqdisk-1.0.1-1.i386.rpm, current version is 1.0.1 ) to a local directory. You can find the rpm in Oracle's OTN site. 3._ Set the environment variable to a group, who should own this binary. Typically it is the "dba" group. export CVUQDISK_GRP=dba 4._ Erase any existing package rpm -e cvuqdisk 5._ Install the rpm rpm -iv cvuqdisk-1.0.1-1.i386.rpm
How do I know about cluvfy commands? The usage text of cluvfy does not show individual commands.
Cluvfy has context sensitive help built into it. Cluvfy shows the most appropriate usage text based on the cluvfy command line arguments. If you type 'cluvfy' on the command prompt, cluvfy displays the high level generic usage text, which talks about valid stage and component syntax. If you type 'cluvfy comp -list', cluvfy will show valid components with brief description on each of them. If you type 'cluvfy comp -help', cluvfy will show detail syntax for each of the valid components. Similarly, 'cluvfy stage -list' and 'cluvfy stage -help' will list valid stages and their syntax respectively. If you type an invalid command, cluvfy will show the appropriate usage for that particular command. For example, if you type 'cluvfy stage -pre dbinst', cluvfy will show the syntax for pre-check of dbinst stage.
Do I have to type the nodelist every time for the CVU commands? Is there any shortcut?
You do not have to type the nodelist every time for the CVU commands. Typing the nodelist for a large cluster is painful and error prone. Here are few short cuts. To provide all the nodes of the cluster, type '-n all'. Cluvfy will attempt to get the nodelist in the following order: 1. If a vendor clusterware is available, it will pick all the configured nodes from the vendor clusterware using lsnodes utility. 2. If CRS is installed, it will pick all the configured nodes from Oracle clusterware using olsnodes utility. 3. In none of the above, it will look for the CV_NODE_ALL environmental variable. If this variable is not defined, it will complain. To provide a partial list(some of the nodes of the cluster) of nodes, you can set an environmental variable and use it in the CVU command. For example: setenv MYNODES node1,node3,node5 cluvfy comp nodecon -n $MYNODES
How do I get detail output of a check?
Cluvfy supports a verbose feature. By default, cluvfy reports in non-verbose mode and just reports the summary of a test. To get detailed output of a check, use the flag '-verbose' in the command line. This will produce detail output of individual checks and where applicable will show per-node result in a tabular fashion.
How do I check network or node connectivity related issues?
Use component verifications commands like 'nodereach' or 'nodecon' for this purpose. For detail syntax of these commands, type cluvfy comp -help on the command prompt. If the 'cluvfy comp nodecon' command is invoked without -i, cluvfy will attempt to discover all the available interfaces and the corresponding IP address & subnet. Then cluvfy will try to verify the node connectivity per subnet. You can run this command in verbose mode to find out the mappings between the interfaces, IP addresses and subnets. You can check the connectivity among the nodes by specifying the interface name(s) through -i argument.
How do I check whether OCFS is properly configured?
You can use the component command 'cfs' to check this. Provide the OCFS file system you want to check through the -f argument. Note that, the sharedness check for the file sytem is supported for OCFS version 1.0.14 or higher.
How do I check user accounts and administrative permissions related issues?
Use admprv component verification command. Refer to the usage text for detail instruction and type of supported operations. To check whether the privilege is sufficient for user equivalence, use '-o user_equiv' argument. Similarly, the '-o crs_inst' will verify whether the user has the correct permissions for installing CRS. The '-o db_inst' will check for permissions required for installing RAC and '-o db_config' will check for permissions required for creating a RAC database or modifying a RAC database configuration.
How do I check minimal system requirements on the nodes?
The component verification command sys is meant for that. To check the system requirement for RAC, use '-p database' argument. To check the system requirement for CRS, use '-p crs' argument.
Is there a way to compare nodes?
You can use the peer comparison feature of cluvfy for this purpose. The command 'comp peer' will list the values of different nodes for several pre-selected properties. You can use the peer command with -refnode argument to compare those properties of other nodes against the reference node.
Why the peer comparison with -refnode says passed when the group or user does not exist?
Peer comparison with the -refnode feature acts like a baseline feature. It compares the system properties of other nodes against the reference node. If the value does not match( not equal to reference node value ), then it flags that as a deviation from the reference node. If a group or user does not exist on reference node as well as on the other node, it will report this as 'matched' since there is no deviation from the reference node. Similarly, it will report as 'mismatched' for a node with higher total memory than the reference node for the above reason.
Why cluvfy reports "unknown" on a particular node?
Cluvfy reports unknown when it can not conclude for sure if the check passed or failed. A common cause of this type of reporting is a non-existent location set for the CV_DESTLOC variable. Please make sure the directory pointed by this variable exists on all nodes and is writable by the user.
What are the known issues with this release?
1._ Shared storage accessibility(ssa) check reports Current release of cluvfy has the following limitations on Linux regarding shared storage accessibility check. a. Currently NAS storage ( r/w, no attribute caching), OCFS( version 1.0.14 or higher ) and scsi disks(if cvuqdisk package is installed) are supported. Note that, 'cvuqdisk' package should be installed only on RedHat Linux 3.0 distribution. Discovery of scsi disks for RedHat Linux 2.1 is not supported. b. For sharedness check on NAS, cluvfy requires the user to have write permission on the specified path. If the cluvfy user does not have write permission, cluvfy reports the path as not-shared. 2._ What database version is supported by CVU? Current CVU release supports only 10g RAC and CRS and is not backward compatible. In other words, CVU can not check or verify pre-10g products. 3._ What Linux distributions are supported? This release supports only RedHat 3.0 Update 2 and RedHat 2.1AS distributions. Note that, the CVU distribution for RedHat 3.0 Update 2 and RedHat 2.1AS are different; they are not binary compatible. In other words, CVU bits for RedHat 3.0 and RedHat 2.1 are not the same. 4._ The component check for node application (cluvfy comp nodeapp ...) command reports node app creation error if the local CRS stack is down. This is a known issue and will be addressed shortly. 5._ CVU does not recongnize the disk bindings ( e.g. /dev/raw/raw1 ) as valid storage paths or identifiers. Please use the underlying disk( e.g. /dev/sdm etc ) for the storage path or identifiers. 6._ Current version of CVU for RedHat 2.1 complains about the missing cvuqdisk package. This will be corrected in the future release. User should ignore this error. Note that, 'cvuqdisk' package should be installed only on RedHat Linux 3.0 distribution. Discovery of scsi disks for RedHat Linux 2.1 is not supported.
If a current customer has an Enterprise License Agreement (ELA), are they entitled to use Oracle RAC One Node?
Yes, assuming the existing ELA/ULA includes Oracle RAC. The license guide states that all Oracle RAC option licenses (not SE RAC) include all the features of Oracle RAC One Node. Customers with existing RAC licenses or Oracle RAC ELA's can use those licenses as Oracle RAC One Node. This amounts to "burning" a Oracle RAC license for Oracle RAC One Node, which is expensive long term. Obviously if the ELA/ULA does not include Oracle RAC, then they are not entitled to use Oracle RAC One Node.
How is Oracle RAC One Node licensed and priced?
Oracle RAC One Node is an option to the Oracle Database Enterprise Edition and licensed based upon the number of CPU's in the server on which it is installed. Current list price is $10,000 per CPU (Check price list).
Unlike the Oracle RAC feature, Oracle RAC One Node is not available with the Oracle Standard Edition.
Oracle RAC One Node licensing also includes the 10-day rule, allowing a database to relocate to another node for up to 10 days per year, without incurring additional licensing fees. This is most often used in the case of failover, or for planned maintenance and upgrading. Only one node in the cluster can be used for the 10-day rule.
Is Oracle RAC One Node supported with 3rd party clusterware and/or 3rd party CFS?
No. Oracle RAC One Node is only supported with with version 11.2 (and above) of Oracle grid infrastructure.
How does RAC One Node compare with traditional cold fail over solutions like HP Serviceguard, IBM HACMP, Sun Cluster and Symantec, and Veritas Cluster Server?
RAC One Node is a better high availability solution than traditional cold fail over solutions.
RAC One Node operates in a cluster but only a single instance of the database is running on one node in the cluster. If that database instance has a problem, RAC One Node detects that and can attempt to restart the instance on that node. If the whole node fails, RAC One Node will detect that and will bring up that database instance on another node in the cluster. Unlike traditional cold failover solutions, Oracle Clusterware will send out notifications (FAN events) to clients to speed reconnection after failover. 3rd-party solutions may simply wait for potentially lengthy timeouts to expire.
RAC One Node goes beyond the traditional cold fail over functionality by offering administrators the ability to proactively migrate instances from one node in the cluster to another. For example, lets say you wanted to do an upgrade of the operating system on the node that the RAC One Node database is running on. The administrator would activate "OMotion," a new Oracle facility that would migrate the instance to another node in the cluster. Once the instance and all of the connections have migrated, the server can be shut down, upgraded and restarted. OMotion can then be invoked again to migrate the instance and the connections back to the now-upgraded node. This non-disruptive rolling upgrade and patching capability of RAC One Node exceeds the current functionality of the traditional cold fail over solutions.
Also, RAC One Node provides a load balancing capability that is attractive to DBAs and Sys Admins. For example, if you have two different database instances running on a RAC One Node Server and it becomes apparent that the load against these two instances is impacting performance, the DBA can invoke OMotion and migrate one of the instances to another less-used node in the cluster. RAC One Node offers this load balancing capability, something that the traditional cold fail over solutions do not.
Lastly,many 3rd-party solutions do not support ASM storage. This can slow down failover, and prevent consolidation of storage across multiple databases, increasing the management burden on the DBA.
The following table summarizes the differences between RAC One Node and 3rd-party fail over solutions:
Feature
RAC One Node
EE plus 3rd Party Clusterware
Out of the box experience
RAC One Node provides everything necessary to implement database failover.
3rd-party fail over solutions require a separate install and a separate management infrastructure.
Single Vendor
RAC One Node is 100% supported by Oracle
EE is supported by Oracle, but the customer must rely on the 3rd-party to support their clusterware.
Fast failover
RAC One Node supports FAN Events, to send notifications to clients after failovers and to speed re-connection
3rd-party fail over solutions rely on timeouts for clients to detect failover and initiate a reconnection. It could take several minutes for a client to detect there had been a failover.
Rolling DB patching, OS, Clusterware, ASM patching and upgrades
RAC One Node can migrate a database from one server to another to enable online rolling patching. Most connections should migrate with no disruption.
3rd-party solutions must be failed over from one node to another, which means all connections will be dropped and must reconnect. Some transactions will be dropped and must reconnect. Reconnection could take several minutes.
Workload Management
RAC One Node can migrate a database from one server to another while online to enable load balancing of databases across servers in the cluster. Most connections should migrate with no disruption.
3rd-party solutions must be failed over from one node to another, which means all connections will be dropped and must reconnect. Some transactions will be dropped and must reconnect. Reconnection could take several minutes.
Online scale out
Online upgrade to multi-node RAC
Complete reinstall including Oracle Grid Infrastructure is required.
Standardized tools and processes
RAC and RAC One Node use the same tools, management interfaces, and processes.
EE and RAC use different tools, management interfaces, and processes. 3rd-party clusterware requires additional interfaces.
Storage virtualization
RAC One Node supports use of ASM to virtualize and consolidate storage. Because it’s shared across nodes, it eliminates the lengthy failover of volumes and file systems
Traditional 3rd-party solutions rely on local file systems and volumes that must be failed over. Large volumes can take a long time to fail over. Dedicated storage is also more difficult to manage.
How does RAC One Node compare with a single instance Oracle Database protected with Oracle Clusterware?
Feature
RAC One Node
EE plus Oracle Clusterware
Out of the box experience
RAC One Node is a complete solution that provides everything necessary to implement a database protected from failures by a failover solution.
Using Oracle Clusterware to protect an EE database is possible by customizing some sample scripts we provide to work with EE. This requires custom script development by the customer, and they need to set up the environment and install the scripts manually.
Supportability
RAC One Node is 100% supported
While EE is 100% supported, the scripts customized by the customer are not supported by Oracle.
DB Control support
RAC One Node fully supports failover of DB Control in a transparent manner
DB Control must be reconfigured after a failover (unless the customer scripts are modified to support DB Control failover)
Rolling DB patching, OS, Clusterware, ASM patching and upgrades
RAC One Node can online migrate a database from one server to another to enable online rolling patching. Most connections should migrate with no disruption
EE must be failed over from one node to another, which means all connections will be dropped and must reconnect. Some transactions will be dropped and must reconnect. Reconnection could take several minutes.
Workload Management
RAC One Node can online migrate a database from one server to another to enable load balancing of databases across servers in the cluster. Most connections should migrate with no disruption
EE must be failed over from one node to another, which means all connections will be dropped and must reconnect. Some transactions will be dropped and must reconnect. Reconnection could take several minutes.
Online scale out
Online upgrade to multi-node RAC
Take DB outage and re-link to upgrade to multi-node RAC, re-start DB.
Standardized tools and processes
RAC and RAC One Node use same tools, management interfaces, and processes
EE and RAC use different tools, management interfaces, and processes
What is Oracle Real Application Clusters One Node (RAC One Node)?
Oracle RAC One Node is an option available with Oracle Database 11g Release 2. Oracle RAC One Node is a single instance of Oracle RAC running on one node in a cluster.
This option adds to the flexibility that Oracle offers for reducing costs via consolidation. It allows customers to more easily consolidate their less mission critical, single instance databases into a single cluster, with most of the high availability benefits provided by Oracle Real Application Clusers (automatic restart/failover, rolling patches, rolling OS and clusterware upgrades), and many of the benefits of server virtualization solutions like VMware.
RAC One Node offers better high availability functionality than traditional cold failover cluster solutions because of a new Oracle technology Omotion, which is able to intelligently relocate database instances and connections to other cluster nodes for high availability and system load balancing.
If I add or remove nodes from the cluster, how do I inform RAC One Node?
You must re-run raconeinit to update the candidate server list for each RAC One Node Database.
Is RAC One Node supported with database versions prior to 11.2?
No. RAC One Node requires at least version 11.2 of Oracle Grid Infrastructure, and the RAC One Node database must be at least 11.2. Earlier versions of the rdbms can coexist with 11.2 RAC One Node databases.
How do I get Oracle Real Application Clusters One Node (Oracle RAC One Node)?
Oracle RAC One Node is only available with Oracle Database 11g Release 2. Oracle Grid Infrastructure for 11g Release 2 must be installed as a prerequisite. Download and apply Patch 9004119 to your Oracle RAC 11g Release 2 home in order to obtain the code associated with RAC One Node. (this patch was released after 11.2.0.1 was released and is only available for Linux). Support for other platforms will be added with 11.2.0.2. The documentation is the Oracle RAC One Node User Guide
Where do I find the documentation for RAC One Node?
RAC One Node was released as a patch after the original GA release of Oracle Database 11g Release 2. RAC One Node documentation will be included in the next doc set refresh. Please refer to Oracle RAC One Node User Guide
Does Enterprise Manager Support RAC One Node?
Yes, you can use Enterprise Manager DB Console to manage RAC One Node databases. Note that in 11.2.0.1, when you run raconeinit, the instance name is changed. you should either configure EM DB Console after running raconeinit, and after every instance relocation (Omotion) or failover, the EM DB Console will need to be reconfigured to see the new instance on the new node. This can be done using emca and is the same as with adding any new DB to the configuration. In the future, 11.2.0.2, EM will support RAC One Node database out of the box. so EM will be able to detect when the instance is migrated or failed over to another node.
How does RAC One Node compare with database DR products like DataGuard or Golden Gate?
The products are entrely complementary. RAC One Node is designed to protect a single database. It can be used for rolling database patches, OS upgrades/patches, and grid infrastructure (ASM/Clusterware) rolling upgrades and patches. This is less disruptive than switching to a datbase replica. Switching to a replica for patching, or for upgrading the OS or grid infrastructure requires that you choose to run Active/Active (and deal with potential conflicts) or Active/Passive (and wait for work on the active primary database to drain before allowing work on the replica). You need to make sure replication supports all data types you are using. You need to make sure the replica can keep up with your load. You need to figure out how to re-point your clients to the replica (not an issue with RAC One Node because it's the same database, and we use VIPs). And lastly, RAC One Node allows a spare node to be used 10 days per year without licensing. Our recommendation is to use RAC or RAC One Node to protect from local failures and to support rolling maintenance activities. Use Data Guard or replication technology for DR, data protection, and for rolling database upgrades. Both are required as part of a comprehensive HA solution.
How do I install the command line tools for RAC One Node?
The command line tools are installed when you install the RAC One Node patch 9004119 on top of 11.2.0.1.
Are we certifying applications specifically for RAC One Node?
No. If the 3rd party application is certified for Oracle Database 11g Release 2 Enterprise Edition, it is certified for RAC One Node.
Does Rac One Node make sense in a stretch cluster environment?
Yes. However, remember that most stretch cluster implementations also implement deparate storage arrays at both locations. So write latency is still an issue that must be considered since ASM is still writing blocks to both sites. Anything beyond a metro area configuration is likely to introduce too much latency for the application to meet performance SLAs.
How does RAC One Node compare with virtualization solutions like VMware?
RAC One Node offers greater benefits and performance than VMware in the following ways:
- Server Consolidation: VMware offers physical server consolidation but imposes a 10%+ processing overhead to enable this consolidation and have the hypervisor control access to the systems resources. RAC One Node enables both physical server consolidation as well as database consolidation without the additional overhead of a hypervisor-based solution like VMware.
- High Availability: VMware offers the ability to fail over a failed virtual machine – everything running in that vm must be restarted and connections re-established in the event of a virtual machine failure. VMware cannot detect a failed process within the vm – just a failed virtual machine. RAC One Node offers a finer-grained, more intelligent and less disruptive high availability model. RAC One Node can monitor the health of the database within a physical or virtual server. If it fails, RAC One Node will either restart it or migrate the database instance to another server. Oftentimes, database issues or problems will manifest themselves before the whole server or virtual machine is affected. RAC One Node will discover these problems much sooner than a VMware solution and take action to correct it. Also, RAC One Node allows database and OS patches or upgrades to be made without taking a complete database outage. RAC One Node can migrate the database instance to another server, patches or upgrades can be installed on the original server and then RAC One Node will migrate the instance back. VMware offers a facility, Vmotion, that will do a memory-to-memory transfer from one virtual machine to another. This DOES NOT allow for any OS or other patches or upgrades to occur in a non-disruptive fashion (an outage must be taken). It does allow for the hardware to be dusted and vacuumed, however.
- Scalability: VMware allows you to “scale” on a single physical server by instantiating additional virtual machines – up to an 8-core limit per vm. RAC One Node allows online scaling by migrating a RAC One Node implementation from one server to another, more powerful server without taking a database outage. Additionally, RAC One Node allows further scaling by allowing the RAC One Node to be online upgraded to a full Real Application Clusters implementation by adding additional database instances to the cluster thereby gaining almost unlimited scalability.
- Operational Flexibility and Standardization: VMware only works on x86-based servers. RAC One Node will be available for all of the platforms that Oracle Real Application Clusters supports including Linux, Windows, Solaris, and AIX, HP-UX.
Can I use Oracle RAC One Node for Standard Edition Oracle RAC?
No, Oracle RAC One Node is only part of Oracle Database 11g Release 2 Enterprise Edition. It is not licensed or supported for use with any other editions.
What is RAC One Node Omotion?
Omotion is a utility that is distributed as part of Oracle RAC One Node. The Omotion utility allows you to move the Oracle RAC One Node instance from one node to another in the cluster. There are several reasons you may want to move the instance such as the node is overloaded so you need to balance the workload by moving the instance, or you need to do some operating system maintenance on the node however you want to eliminate the outage for application users by moving the instance to another node in the cluster.
Can I remove Oracle resources from the cluster? How can I hide unused resources when listing all resources in the cluster?
One must not remove or delete any Oracle resources from the cluster . Oracle resources are defined are typically pre-configured during the installation of Oracle Clusterware / Grid Infrastructure or added in the course of a default installation or configuration process of other Oracle products. With Oracle Database 11g Release 2 Oracle has taken the approach to pre-configure some resources, but activate them (or have them activated) only once required. As long as the components represented by these resources are not used, the Oracle Clusterware proxy resources are set to offline / are disabled, which means, they are not running and should therefore not cause any issues.
How can I hide unused resources when listing all resources in the cluster? If one wants to list only those resources that are actively used in the cluster, the following command can be used:
crsctl stat res -w 'ENABLED != 0' -- the -t option can be used to get a "tabular view"
Note: If ASM is not used for the cluster at all, disable the ASM proxy resource in Oracle Clusterware in order to not list it using this command. To disable the ASM proxy resource in Oracle Clusterware, the "srvctl disable asm [-n (node_name)]" command can be used. If ASM is used to store the Voting Disks and / or OCRs, DB files, or an ACFS file system, ASM must be enabled!
How to use SCAN and node listeners with different ports?
Oracle SCAN was designed to be the Single Client Access entry point to a database cluster and various Oracle databases in this cluster. Its general configuration (a single entry in the DNS resolving to at least three IP addresses) is described in various places in this FAQ.
However, most of these entries assume a simple configuration, regarding the ports and numbers of listeners in the cluster. Basically, the assumption is that 1 SCAN listener, running on 1-3 nodes in the cluster, will work with 1 node listener, running on all of the nodes in the cluster. In addition, most examples assume that both listeners actually use the same port (default 1521).
Quite a few customers, nevertheless, want to use dedicated listeners per database either on the same or a different port. There is no general requirement to do this using an Oracle RAC 11g Release 2, as the overall idea is that any client will use the SCAN as its initial entry point and will then be connected to the respective instance and service on the node this service is most suitably served on using the node listener on this node.
This assumes that the respective database that the instance belongs to and that the service is assigned to uses the correct entries for the LOCAL_LISTENER and REMOTE_LISTENER instance parameters. The defaults for the case described would be: LOCAL_LISTENER points to the node listener on the respective node and the REMOTE_LISTENER points to the SCAN. Example:
remote_listener: cluster1:1521
local_listener:(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.0.61)(PORT=1521))))
Any Oracle 11g Rel. 2 database that is created using the DBCA will use these defaults. In this context, some fundamentals about listeners in general and the listener architecture in Oracle RAC 11g Release 2 need to be understood in order to follow the examples below:
With Oracle RAC 11g Release 2 using SCAN is the default.
SCAN is a combination of an Oracle managed VIP and a listener.
The SCAN listener represents a standard Oracle listener used in a certain way.
As with other listeners, there is no direct communication between the node and the SCAN listeners.
The listeners are only aware of the instances and services served, since the instances (PMON) register themselves and the services they host with the listeners.
The instances use the LOCAL and REMOTE Listener parameters to know which listeners to register with.
Any node listener is recommended to be run out of the Oracle Grid Infrastructure home, although the home that a listener uses can be specified.
Listeners used for a client connection to Oracle RAC should be managed by Oracle Clusterware and should be listening on an Oracle managed VIP.
Given these fundamentals, there does not seem to be a compelling use case, why multiple listeners or dedicated listeners per database should be used with 11g Rel. 2 RAC, even if they where used in previous versions. The most reasonable use case seems to be manageability in a way that some customers prefer to stop a listener to prevent new client connections to an assigned database as opposed to stopping the respective services on the database, which mainly has the same effect (note that the standard database service - the one that is named after the database name - must not be used to connect clients to an Oracle RAC database anyways, although being used in this example for simplicity reasons.)
If the motivation to have this setup is to assign certain listeners as an entry point to certain clients, note that this would defeat the purpose of SCAN and therefore SCAN cannot be used anymore. SCAN only supports one address in the TNS connect descriptor and allows only 1 port assigned to it. This port does not have to be same as the one that is used for the node listeners (which would be the default), but it should only be one port (Bug 10633024 - SRVCTL ALLOWS SPECIFYING MORE THAN ONE PORT FOR SCAN (-P PORT1,PORT2,PORT3) - has been filed for Oracle RAC 11.2.0.2, as this version allows setting more than one port using SRVCTL). Consequently, a typical client TNSNAMES entry for the client to connect to any database in the cluster would look like the following:
testscan1521 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = cluster1)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORCL)
))
In this TNSNAMES entry "cluster1" is the SCAN name, typically registered in the DNS as mentioned. This entry will connect any client using "testscan1521" to any database in the cluster assuming that node listeners are available and the database is configured accordingly using the following configuration:
remote_listener: cluster1:1521
local_listener:(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.0.61)(PORT=1521))))
If the motivation to have dedicated listeners for the database is so that clients would get different connection strings to connect to the database (e.g. different host entries or ports) SCAN cannot be used and the node listeners need to be addressed directly, as it used to be the case with previous versions of Oracle RAC. In this case, the SCAN is basically not used for client connections. Oracle does not recommend this configuration, but this entry will explain its configuration later on.
Change the port of the SCAN listeners only
Note 1: in the following only 1 SCAN listener is used for simplification reasons.
Get the name of the scan listener: srvctl status scan_listener returns: LISTENER_SCAN1
Get the port of the scan listener: lsnrctl status LISTENER_SCAN1 returns: 1521
Change the port of the SCAN listener: srvctl modify scan_listener -p 1541 new port 1541
Restart the SCAN listener: srvctl stop scan_listener followed by srvctl start scan_listener
Double-check using lsnrctl status LISTENER_SCAN1 - this should show port 1541
Note 2: Your SCAN listener does not serve any database instance at this point in time, as the database has not been informed about the change in port for the SCAN or their remote listener. In order to have the database instances register with the SCAN listener using the new port, you must alter the REMOTE_LISTENER entry accordingly:
alter system set remote_listener='cluster1:1541' scope=BOTH SID='*';
alter system register;
Double-check using lsnrctl status LISTENER_SCAN1 that the instances have registered.
With this change the following configuration has been established:
The SCAN listener port has been changed to port 1541 (was: 1521)
The node listeners - here named LISTENER - still use port 1521
In order for clients to be able to connect, change their TNSNAMES.ora accordingly:
testscan1541 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = cluster1)(PORT = 1541))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORCL)
))
Add additional node listeners to the system using different ports
So far, only one node listener (listener name LISTENER) on the respective node VIP (here: 192.168.0.61) on port 1521 has been used. The idea of having dedicated listeners per database would mean that additional node listeners need to be created, using the same IP, but preferably different ports. In order to achieve this configuration, perform the following steps (the Grid Infrastructure software owner should have enough privileges to perform these steps, hence the user is not explicitly mentioned):
Add an additional node listener using port 2011 for example: srvctl add listener -l LISTENER2011 -p 2011
Start the new node listener: srvctl start listener -l LISTENER2011
Double-check using: srvctl status listener -l LISTENER2011
Double-check using: lsnrctl status LISTENER2011
Note 1: The srvctl command "add listener" does allow specifying an Oracle Home that the newly added listener will be running from and yet have this listener be managed by Oracle Clusterware. This entry does not elaborate on these advanced configurations.
Note 2: Your new node listener does not serve any database instance at this point in time, as the database has not been informed that it should connect to the newly created listener. In order to have the database instances register with this listener, you must alter the LOCAL_LISTENER entry for each instance accordingly:
alter system set local_listener='(DESCRIPTION= (ADDRESS_LIST= (ADDRESS=(PROTOCOL=TCP)(HOST=192.168.0.61)(PORT=2011))))' scope=BOTH SID='OCRL1';
alter system register;
Double-check using lsnrctl status LISTENER2011 that the instance has registered.
Note 3: It is crucial to use spaces between the various segments of the command as shwon above (for example). Reason: the database agent in Oracle Clusterware currently determines whether the local_listener or remote_listener have been manually set by a string comparison operation. If the string looks like it is not manually altered, the agent will overwrite these parameters with the default values that it determines on instance startup. In order to prevent a reset of these parameters at instance startup and thereby make this setting persistent across instance starts, slight modifications in the string used for this parameter are required. ER 11772838 has been filed to allow for a more convenient mechanism.
Note 4: As the LOCAL_LISTENER parameter is a per instance parameter, perform this change on all nodes that the database is running on accordingly.
Note 5: This example so far assumed that only one database (ORCL) is used in the system, with the SCAN name "cluster1" and now using "LISTENER2011", listening on port 2011, as the new node listener. Before the new node listener was created, the listener with the name "LISTENER" used to be the default node listener. This listener, listening on port 1521, has not been removed yet and can therefore now be used as a dedicated listener for additional databases added to the system for example. In order to ensure that those databases will use this listener, the LOCAL_LISTENER instance parameter should point to this listener as follows:
local_listener:(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.0.61)(PORT=1521))))
Note 6: The clients' TNSNAMES.ora files do not need to be modified in this case, as the SCAN remains as the primary entry point for clients to connect to databases in the cluster. This is the beauty of SCAN.
With this change the following configuration has been established:
The SCAN listener port remains on port 1541 (was: 1521)
The node listener used by database ORCL is now called LISTENER2011, listening on port 2011
In order for clients to be able to connect to this database, no change to their TNSNAMES.ora is required. They still use:
testscan1541 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = cluster1)(PORT = 1541))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORCL)
))
Even, if more databases are added to the cluster, using the default node listener "LISTENER", still listening on port 1521 in this example, the client TNSNAMES.ora would not change. Again, this is the beauty of SCAN.
Use the node listeners as the primary entry point directly
Continuing the previous example, the following configuration is assumed for the next steps:
The SCAN listener port remains on port 1541 - SCAN name is "cluster1"
The node listener used by database ORCL is now called LISTENER2011, listening on port 2011
The node listener used by database FOOBAR is called LISTENER, listening on port 1521
In order for clients to connect to the databases ORCL and FOOBAR, but not using SCAN, a TNSNAME.ora entry for each database must be used. The pre-Oracle 11g Rel. 2 RAC paradigm must be followed in this case. Hence, one typical TNSNAMES.ora entry for the example used here would look like the following:
ORCL =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = node1)(PORT = 2011))
(ADDRESS = (PROTOCOL = TCP)(HOST = node2)(PORT = 2011))
(ADDRESS = (PROTOCOL = TCP)(HOST = node...)(PORT = 2011))
(ADDRESS = (PROTOCOL = TCP)(HOST = nodeN)(PORT = 2011))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORCL)
))
FOOBAR =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = node1)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = node2)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = node...)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = nodeN)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = FOOBAR)
))
Each database (ORCL and FOOBAR) on the other hand must be adjusted to register with the local and remote listener(s) logically "assigned" to the respective database. This means for ORCL's first instance:
local_listener:(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=node1)(PORT=2011))))
remote_listener:(DESCRIPTION=(ADDRESS_LIST=(ADDRESS = (PROTOCOL = TCP)(HOST = node2)(PORT = 2011))(ADDRESS = (PROTOCOL = TCP)(HOST = node...)(PORT = 2011))(ADDRESS = (PROTOCOL = TCP)(HOST = nodeN)(PORT = 2011))))
For FOOBAR's first instance this means:
local_listener:(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=node1)(PORT=1521))))
remote_listener:(DESCRIPTION=(ADDRESS_LIST=(ADDRESS = (PROTOCOL = TCP)(HOST = node2)(PORT = 1521))(ADDRESS = (PROTOCOL = TCP)(HOST = node...)(PORT = 1521))(ADDRESS = (PROTOCOL = TCP)(HOST = nodeN)(PORT = 1521))))
Note 1: Unlike when using SCAN, you can use a server side TNSNAMES.ora to resolve the local and remote listener parameters as it used to be recommended for pre-Oracle RAC 11g Release 2 databases. With Oracle RAC 11g Rel. 2, the use of SCAN would make this unnecessary.
Note 2: Avoiding the necessity to set parameters for each database and to change those every time the cluster and the databases change with respect to he number of nodes, is the reason you should use SCAN.
How to change the SCAN configuration after the Oracle Grid Infrastructure 11g Release 2 installation is complete?
Use SRVCTL to modify the SCAN.
In order to make the cluster aware of the modified SCAN configuration, delete the entry in the hosts-file or make sure that the new DNS entry reflects (depending on where you have setup your SCAN name resolution in the first place) and then issue: "srvctl modify scan -n " as the root user on one node in the cluster.
The scan_name provided can be the existing fully qualified name (or a new name), but should be resolved through DNS, having 3 IPs associated with it. The remaining reconfiguration is then performed automatically.
A successful reconfiguration will result in 3 SCAN VIPs and 3 SCAN_LISTENERS in the cluster, enabling to load balancing of connections to databases running in the cluster. Each SCAN_LISTENER listens on one of the SCAN VIP addresses.
Most changes to the SCAN configuration can be performed using 'srvctl modify scan'. This includes name changes (changes to the SCAN name) and IP address changes (assuming that the new IP addresses are taken from the same subnet as the old ones). Removing and adding-back the SCAN configuration should not be required. However, the SCAN listeners may need to be restarted using 'srvctl stop / start scan' to reflect an IP address change, if the IP addresses were changed.
Also note that updating the SCAN name might require to change the remote_listener settings for the various Oracle RAC databases in the cluster, since the default configuration would be to have the remote_listener parameter for an Oracle RAC database point to the SCAN name. If the SCAN name changes, the parameter needs to be updated manually for each database.
Why am I only using 1 out of 3 SCAN IP addresses?
The SCAN name must be set up to round robin across 3 IP addresses. This requires a SCAN name resolution via either DNS or the new Oracle Grid Naming Service (GNS).
Using the hosts-file (Linux: /etc/hosts), you will only get 1 SCAN IP and you cannot work around this other than using the formerly mentioned DNS or GNS based name resolution.
Trying to work around this restriction by setting up a hosts-file entry like the following one will not work as expected and should therefore be avoided, since it is a non-conformant use of the hosts-file:
# SCAN addr
192.21.101.74 rac16-cluster.example.com rac16-cluster
192.21.101.75 rac16-cluster.example.com rac16-cluster
192.21.101.76 rac16-cluster.example.com rac16-cluster
Even with such a hosts-file entry, you will only get 1 SCAN VIP and 1 SCAN Listener.
IF you have set up a DNS based SCAN name resolution and you still notice that the client would only use one IP address (out of the three IP addresses that are resolved via SCAN), make sure that the SCAN addresses are returned by the DNS in a round robin manner. You can check the SCAN configuration in DNS using “nslookup”. If your DNS is set up to provide round-robin access to the IPs resolved by the SCAN entry, then run the “nslookup” command at least twice to see the round-robin algorithm work. The result should be that each time, the “nslookup” would return a set of 3 IPs in a different order.
How to install Oracle Grid Infrastructure using SCAN without using DNS?
Oracle Universal Installer (OUI) enforces providing a SCAN resolution during the Oracle Grid Infrastructure installation, since the SCAN concept is an essential part during the creation of Oracle RAC 11g Release 2 databases in the cluster. All Oracle Database 11g Release 2 tools used to create a database (e.g. the Database Configuration Assistant (DBCA), or the Network Configuration Assistant (NetCA)) would assume its presence. Hence, OUI will not let you continue with the installation until you have provided a suitable SCAN resolution.
However, in order to overcome the installation requirement without setting up a DNS-based SCAN resolution, you can use a hosts-file based workaround. In this case, you would use a typical hosts-file entry to resolve the SCAN to only 1 IP address and one IP address only. It is not possible to simulate the round-robin resolution that the DNS server does using a local host file. The host file look-up the OS performs will only return the first IP address that matches the name. Neither will you be able to do so in one entry (one line in the hosts-file). Thus, you will create only 1 SCAN for the cluster. (Note that you will have to change the hosts-file on all nodes in the cluster for this purpose.)
This workaround might also be used when performing an upgrade from former (pre-Oracle Database 11g Release 2) releases. However, it is strongly recommended to enable the SCAN configuration as described under “Option 1” or “Option 2” above shortly after the upgrade or the initial installation. In order to make the cluster aware of the modified SCAN configuration, delete the entry in the hosts-file and then issue: "srvctl modify scan -n " as the root user on one node in the cluster. The scan_name provided can be the existing fully qualified name (or a new name), but should be resolved through DNS, having 3 IPs associated with it, as discussed. The remaining reconfiguration is then performed automatically.
How can I add more SCAN VIPs or listeners not using DNS?
You can only create the 3 SCAN VIPs and 3 SCAN Listeners across the cluster, if you have a DNS alias either at installation time or later. You need to resolve the SCAN Name to those formerly mentioned 3 IP addresses at the moment of creation or when modifying the SCAN. This is how they get created - the IPs that are resolved by the SCAN DNS entry are read and the respective VIPs get created.
IF you have no DNS at all at hand at any time, especially not for the servers in your cluster, you will not get 3 SCAN VIPs in your cluster and hence you will have only 1 VIP, which can be considered a single point of failure.
This means that you have 2 choices: You can either live with this configuration and the respective consequences OR you can fall back to using the nodes VIPs of the cluster to connect your clients to, neither of which is recommended, as mentioned in My Oracle Support note with DOC-Id. 887522.1 for example.
For more information on how to change the SCAN confiuration after the installation is complete using srvctl, please, see the RAC FAQ entry titled: "How to change the SCAN configuration after the Oracle Grid Infrastructure 11g Release 2 installation is complete?"
Is it recommended that we put the OCR/Voting Disks in Oracle ASM and, if so, is it preferable to create a separate disk group for them?
With Oracle Grid Infrastructure 11g Release 2, it is recommended to put the OCR and Voting Disks in Oracle ASM, using the same disk group you use for your database data. For the OCR it is also recommended to put another OCR location into a different disk group (typically, the Fast Recovery Area disk group, a.k.a. FRA) to provide additional protection against logical corruption, if available.
Using the same disk groups for the Oracle Clusterware files (OCR and Voting Disks) simplifies (you do not have to create special devices to store those files) and centralizes the storage management (all Oracle related files are stored and managed in Oracle ASM), using the same characteristics for the data stored.
If the Voting Disks are stored in an Oracle ASM disk group, the number of Voting Disks that will be created in this disk group and for the cluster is determined by the redundancy level of the respective disk group. For more information, see Voting Files stored in ASM - How many disks per disk group do I need? The Voting Disks for a particular cluster can only reside in one disk group.
In case "external redundancy" has been chosen for the disk group that holds the database data, it is assumed that an external mechanism (e.g. RAID) is used to protect the database data against disk failures. The same mechanism can therefore be used to protect the Oracle Clusterware files, including the Voting Disk (only one Voting Disk is created in an "external redundancy disk group").
Under certain circumstances, one may want to create a dedicated disk group for the Oracle Clusterware files (OCR and Voting Disks), separated from the existing database data containing disk groups. This should not be required, but can be configured. Potential scenarios include, but are not limited to:
A 1:1 relationship between disk groups and databases is preferred and disk groups are generally not shared amongst databases.
The backup and recovery for individual databases (more than one in the cluster) is based on a snapshot restore mechanism (BCVs). This approach is most likely used in conjunction with a 1:1 disk group to database relationship as mentioned before.
Certain and frequent system specific maintenance tasks uncommonly require to unmount specific, database data containing disk groups. This scenario can most likely be avoided using a different approach for those maintenance tasks.
A higher protection level than the one provided for the "external redundancy disk groups" and therefore for the database data is for some reason required for the Oracle Clusterware files.
How to efficiently recover from a loss of an Oracle ASM disk group containing the Oracle Clusterware files?
If an Oracle ASM disk group containing Oracle database data and the Oracle Clusterware files is lost completely, the system needs to be restored starting with the restore of the Oracle Clusterware files affected.
Note: Oracle recommends to have two disk groups as a standard deployment scenario: the database data containing disk group (commonly referred to as the DATA disk group) and the backup data containing disk group (commonly referred to as the FRA disk group).In this configuration, the Oracle Voting Files(s) and the first Oracle Cluster Registry (OCR) location should share the same disk group as the Oracle Database data, here the DATA disk group. A second OCR location should be placed into the second disk group, here FRA, using "ocrconfig -add +FRA" as root, while the cluster is running.
A complete failure of the FRA disk group would be without effect for the overall cluster operation in this case. A complete failure of the DATA disk group instead will require a restore of the Oracle Voting Files and the Oracle database data that were formerly stored in this disk group.
The most efficient restore procedure in this case is outlined as follows:
Start the cluster in exclusive mode on one node using "crsctl start crs -excl" (root access required).
Ensure that the cluster is running properly using "crsctl check crs" and that the FRA disk group is mounted. The FRA disk group contains the copy of the OCR that contains a backup of the Voting Disk data required to restore the Voting Disk(s).
IF the Cluster Ready Service Daemon (CRSD) is not running AND an "ocrcheck" fails, you will need to mark the FRA disk group as the only surviving OCR location using "ocrconfig -overwrite", followed by a "crsctl stop crs" to stop the cluster. You will then need to restart the cluster on one node in exclusive mode again using "crsctl start crs -excl" (root access required), since the Voting Disks still need to be restored.
Use "crsctl query css votedisk" to retrieve the list of voting files currently defined.
Use "crsctl replace votedisk +FRA" assuming the best practices configuration to restore the Voting Files into the FRA disk group, since the DATA disk group has not been restored yet. The Voting Files can be replaced later, if required.
Stop the cluster using "crsctl stop crs".
Start the cluster in normal mode using "crsctl start crs" - on all nodes in the cluster, as desired and ensure proper cluster operation using "crsctl check crs".
Re-create the DATA disk group using the appropriate method foreseen in your restore procedure. IF this procedure does not foresee to restore the OCR in the DATA disk group (most likely), add the second OCR location (the first location is now in the FRA disk group) using "ocrconfig -delete +DATA", followed by "ocrconfig -add +DATA" (note: the DATA disk group must be mounted on all nodes in the cluster at this time). The re-creation of the data in an Oracle ASM disk group is typically performed by re-creating the DATA disk group and restoring the database data as required and documented.
Note: In case your Backup and Recovery scenario is based on BCV copies of the Oracle ASM disk groups, the same procedure as described above applies, except for the last step:
To restore the DATA disk group, use the BCV copy and mount the disk group once re-created. With the restore of the DATA disk group former Oracle Clusterware files are restored as well. This is without effect for the Voting Disks. Remaining, former Voting Disk data in the freshly restored DATA disk group is automatically discarded. The OCR location being restored with the DATA disk group is automatically synced with the OCR location present in the FRA disk group, latest at the next cluster restart or when a new OCR writer is chosen.
How do I explain the following phrase in the "Oracle® Clusterware Administration and Deployment Guide 11g Release 2 (11.2)" to a customer?
Page 2-27:"If Oracle ASM fails, then OCR is not accessible on the node on which Oracle ASM failed, but the cluster remains operational. The entire cluster only fails if the Oracle ASM instance on the OCR master node fails, if the majority of the OCR locations are in Oracle ASM, and if there is an OCR read or write access, then the crsd stops and the node becomes inoperative."
This was a documentation bug and has been fixed.
Here is the updated write up (posted in the online version):
If an Oracle ASM instance fails on any node, then OCR becomes unavailable on that particular node. If the crsd process running on the node affected by the Oracle ASM instance failure is the OCR writer, the majority of the OCR locations are stored in Oracle ASM, and you attempt I/O on OCR during the time the Oracle ASM instance is down on this node, then crsd stops and becomes inoperable. Cluster management is now affected on this particular node. Under no circumstances will the failure of one Oracle ASM instance on one node affect the whole cluster.
If the root.sh script fails on a node during the install of the Grid Infrastructure with Oracle Database 11g Release 2, can I re-run it?
Yes, however you should first fix the problem that caused it to fail, only then run:
GRID_HOME/crs/install/rootcrs.pl -delete -force
Then rerun root.sh
Is the GNS recommended for most Oracle RAC installations?
The Grid Naming Service (GNS) is a part of the Grid Plug and Play feature of Oracle RAC 11g Release 2. It provides name resolution for the cluster. If you have a larger cluster (greater than 4-6 nodes) or a requirement to have a dynamic cluster (you expect to add or remove nodes in the cluster), then you should implement GNS. If you are implementing a small cluster 4 nodes or less, you do not need to add GNS. Note: Select GNS during install assumes that you have a DHCP server running on the public subnet where Oracle Clusterware can obtain IP addresses for the Node VIPs and the SCAN VIPs.
What is Cluster Health Monitor (IPD/OS)?
This tool (formerly known as Instantaneous Problem Detection tool) is designed to detect and analyze operating system (OS) and cluster resource related degradation and failures in order to bring more explanatory power to many issues that occur in clusters where Oracle Clusterware and Oracle RAC are running such as node eviction.
It tracks the OS resource consumption at each node, process, and device level continuously. It collects and analyzes the cluster-wide data. In real time mode, when thresholds are hit, an alert is shown to the operator. For root cause analysis, historical data can be replayed to understand what was happening at the time of failure.
For more information on Cluster Health Monitor (IPD/IO), see this publicly available Technical White Paper on OTN: Overview of Cluster Heath Monitor (IPD/OS)
What OS does Cluster Health Monitor (IPD/OS) support?
Cluster Health Monitor (IPD/OS) is a standalone tool that should be installed on all clusters where you are using Oracle Real Application Clusters (RAC). It is independent of the Oracle Database or Oracle Clusterware version used.
Cluster Health Monitor (IPD/OS) is currently supported on Linux (requires Linux Kernel version greater than or equal to 2.6.9) and Windows (requires at least Windows Server 2003 with service pack 2).
It supports both, 32-bit and 64-bit installations. The client installation requires the 32-bit Java SDK.
What is Oracle’s goal in developing QoS Management?
QoS Management is a full Oracle stack development effort to provide effective runtime management of datacenter SLAs by ensuring when there are sufficient resources to meet all objectives they are properly allocated and should demand or failures exceed capacity that the most business critical SLAs are preserved at the cost of less critical ones.
What type of applications does Oracle QoS Management manage?
QoS Management is currently able to manage OLTP open workload types for database applications where clients or middle tiers connect to the Oracle database through OCI or JDBC. Open workloads are those whose demand is unaffected by increases in response time and are typical of Internet-facing applications.
What does QoS Management manage?
In datacenters where applications share databases or databases share servers, performance is made up of the sum of the time spent using and waiting to use resources. Since an application’s use of resources is controlled during development, test, and tuning it cannot be managed at runtime; however the wait for resources can. QoS Management manages resource wait times.
What types of resources does QoS Management manage?
Currently QoS Management manages CPU resources both within a database and between databases running on shared or dedicated servers. It also monitors wait times for I/O, Global Cache, and Other database waits.
What type of user interfaces does QoS Management support?
QoS Management is integrated into Enterprise Manager Database Control 11g Release 2 and Enterprise Manager 12c Cloud Control and is accessible from the cluster administration page.
What QoS Management functionality is in Oracle Enterprise Manager?
Enterprise Manger supports the full range of QoS Management functionality organized by task. A Policy Editor wizard presents a simple workflow that specifies the server pools to manage; defines performance classes that map to the database applications and associated SLAs or objectives, and specifies performance policies that contain performance objectives and relative ranking for each performance class and baseline server pool resource allocations. An easy to monitor dashboard presents the entire cluster performance status at a glance as well as recommended actions should resources need to be re-allocated due to performance issues. Finally a set of comprehensive graphs track the performance and metrics of each performance class.
What types of performance objectives can be set?
QoS Management currently supports response time objectives. Response time objectives up to one second for database client requests are supported. Additional performance objectives are planned for future releases.
Does QoS Management require any specific database deployment?
Oracle databases must be created as RAC or RAC One Node Policy-Managed databases. This means the databases are deployed in one or more server pools and applications and clients connect using CRS-managed database services. Each managed database must also have Resource Manager enabled and be enabled for QoS Management. It is also recommended that connection pools that support Fast Application Notification (FAN) events be used for maximum functionality and performance management.
What are Server Pools?
Server Pools are a new management entity introduced in Oracle Clusterware 11g to give IT administrators the ability to better manage their applications and datacenters along actual workload lines. Server Pools are a logical container, where like hardware and work can be organized and given importance and availability semantics. This allows administrators as well as QoS Management to actively grow and shrink these groups to meet the hour-to-hour, day-to-day application demands with optimum utilization of available resources. The use of Server Pools does not require any application code changes, re-compiling or re-linking. Server Pools also allow older non-QoS Management supported databases and middleware to co-exist in a single cluster without interfering with the management of newer supported versions.
What methods does QoS Management support for classifying applications and workloads?
QoS Management use database entry points to “tag” the application or workload with user-specified names. Database sessions are evaluated against classifiers that are sets of Boolean expressions made up of Service Name, Program, User, Module and Action.
What is the overhead of using QoS Management?
The QoS Management Server is a set of Java MBeans that run in a single J2EE container running on one node in the cluster. Metrics are retrieved from each database once every five seconds. Workload classification and tagging only occurs at connect time or when a client changes session parameters. Therefore the overhead is minimal and is fully accounted for in the management of objectives.
Does QoS Management negatively affect an application’s availability?
No, the QoS Management server is not in the transaction path and only adjusts resources through already existing database and cluster infrastructure. In fact, it can improve availability by distributing workloads within and cluster and prevent node evictions caused my memory stress with its automatic Memory Guard feature.
What happens should the QoS Management Server fail?
The QoS Management Server is a managed Clusterware singleton resource that is restarted or failed over to another node in the cluster should it hang or crash. Even if a failure occurs, there is no disruption to the databases and their workloads running in the cluster. Once the restart completes, QoS Management will continue managing in the exact state it was when the failure occurred.
What is Memory Guard and how does it work?
Memory Guard is an exclusive QoS Management feature that uses metrics from Cluster Health Monitor to evaluate the stress of each server in the cluster once a minute. Should it detect a node has over-committed memory, it will prevent new database requests from being sent to that node until the current load is relieved. It does this my turning off the services to that node transactionally at which point existing work will begin to drain off. Once the stress is no longer detected, services will automatically be started and new connections will resume.
How does QoS Management enable the Private Database Cloud?
The Private Database Cloud fundamentally depends upon shared resources. Whether deploying a database service or a separate database, both depend upon being able to deliver performance with competing workloads. QoS Management provides both the monitoring and management of these shared resources, thus complementing the flexible deployment of databases as a service to also maintain a consistent level of performance and availability.
Which versions of Oracle databases does QoS Management support?
QoS Management is supported on Oracle RAC EE and RAC One EE databases from 11g Release 2 (11.2.0.2) forward deployed on Oracle Exadata Database Machine. It is also supported in Measure-Only Mode with Memory Guard support on Oracle RAC EE and RAC One EE databases from 11g Release 2 (11.2.0.3) forward. Please consult the Oracle Database License Guide for details.
Is this a product to be used by an IT administrator or DBA?
The primary user of QoS Management is expected to be the IT or systems administrator that will have QoS administrative privileges on the RAC cluster. As QoS Management actively manages all of the databases in a cluster it is not designed for use by the DBA unless that individual also has the cluster administration responsibility. DBA level experience is not required to be a QoS Management administrator.
Where can I find documentation for QoS Management?
The Oracle Database Quality of Service Management User’s Guide is the source for documentation and covers all aspects of its use. It is currently delivered as part of the Oracle Database Documentation Library starting in 11g Release 2.
Show Related Information Related
Products
· Oracle Database Products > Oracle Database > Oracle Database > Oracle Server - Enterprise Edition
Keywords
CLUSTER MANAGER; CONNECTION LOAD BALANCING; FAILOVER; FAST APPLICATION NOTIFICATION; FAST CONNECTION FAILOVER; NOTIFICATION; ORACLE PROCESS MANAGER AND NOTIFICATION; STANDARD EDITION
Errors
RFC-1918; ORA-29740; ORA-3113; ORA-1031; SDK.CRS; CRS-215